【创意工坊】试用 dify x oceanbase 构建应用级的 ai 助手-c7电子娱乐
背景一
前几天写了一篇博客《试用 oceanbase 4.3.3 构建 <黑神话:悟空> 智能游戏助手》,文中简述了向量数据库和 ai 大模型的关系,本文中不再赘述。
背景二
上次的实验放出来之后,有很多用户都参与了试用,并在论坛、博客纷纷发布试用体验。前两天看到有用户发文表示还不够过瘾,希望我们能够继续打磨一下这个实验项目。
所以身边的同事策划了一个 “dify x oceanbase 实验方案”,想在 oceanbase 数据库支持向量能力的基础上,借助 dify 这个开源的 llm 应用开发平台,让用户通过白屏拖拽的方式,就能够轻松构建和运营生成式的 ai 应用。相比上次的实验,这次会有一些变化:
- 个人测试环境里只需要有一个 docker,搭建便捷。
- rag 机器人支持定制,还支持通过白屏管理多个知识库。
- 支持通过 dify x oceanbase 创建多种 ai 应用,远不止 rag 聊天机器人,可以继续深入探索其他功能。
- 简而言之:可以开门接客了(不仅可以私人使用,甚至可以上 “生产”,在工作团队里使用)。
今天抽空儿来试用下新方案,构建一个 “应用级” 的 ai 助手,顺便做一些记录,先替大家趟趟坑。
背景三
oceanbase 在关系型数据库模型的基础上,将向量作为一种数据类型,使得在 oceanbase 一款数据库中,能够同时针对向量数据和常规的结构化数据进行高效的存储和检索。
在项目中,会使用 oceanbase 建立 hnsw (hierarchical navigable small world) 向量索引来实现高效的向量检索,帮助我们快速找到与用户问题最相关的文档片段。
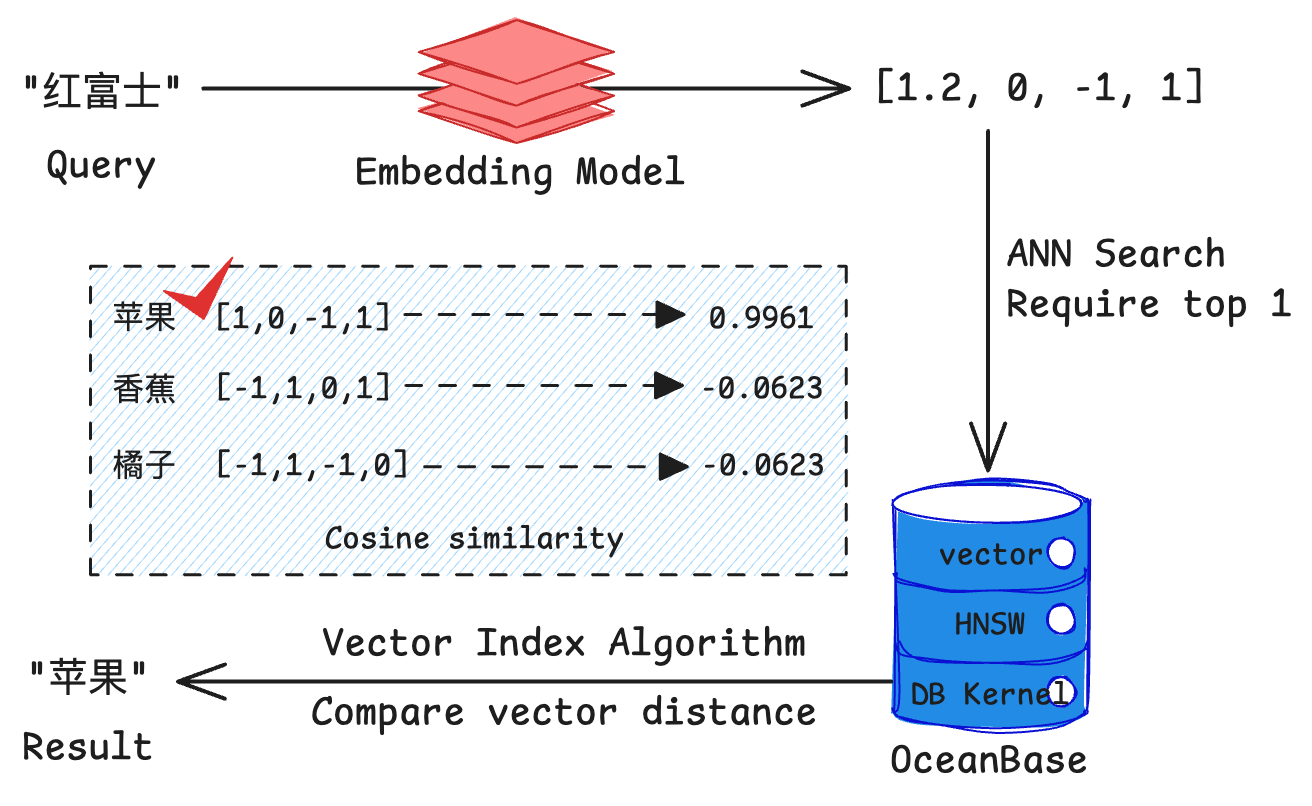
向量检索是在向量数据库中快速找到与查询向量最相似的向量的技术,其核心特点包括:
- 基于向量间的距离(如欧氏距离)或相似度(如余弦相似度)进行搜索。
- 通常使用近似最近邻(approximate nearest neighbor, ann)算法来提高检索效率。
- oceanbase 4.3.3 支持 hnsw 算法,这是一种高效的 ann 算法。
- 使用 ann 可以快速从百万甚至亿级别的向量中找到近似最相似的结果。
- 相比传统关键词搜索,向量检索能更好地理解语义相似性。
背景四
dify 是一个开源的 llm 应用开发平台,直观的界面结合了 ai 工作流、rag 管道、agent、模型管理、可观测性功能等,可以快速从原型到生产。oceanbase 从 4.3.3 版本开始支持了向量数据类型的存储和检索,在 dify 0.11.0 中开始支持使用 oceanbase 作为其向量数据库。
在 fork 出来的 dify 代码仓库 中进行相应的修改之后,dify 支持使用 mysql 协议的数据库存储结构化数据。因此,oceanbase 作为一款多模数据库,可以很好地支持 dify 对结构化数据和向量数据的存取需求,有力地支撑其上 llm 应用的开发和落地。
通过 dify x oceanbase 构建应用级的 ai 助手
上面讲了这么多背景,部署过程这里就稍微简单些,根据 来就行。文档中的实验流程写的十分详细,这里不再赘述。
趟坑记录
想起传统相声里有个段子。
问:“一个老人只有一颗牙,为什么吃东西还塞牙了?” 。
答:“因为吃的是藕” 。
这次因为环境中只需要装一个 docker,本以为吃着火锅唱着歌就能搞好,但是天有不测风云,还是踩到了坑(真不是没坑硬踩)。这个坑只和特定版本的 mac 系统有关,绝大部分人应该都不会遇到,大家不感兴趣的话,可以直接跳过这部分内容。
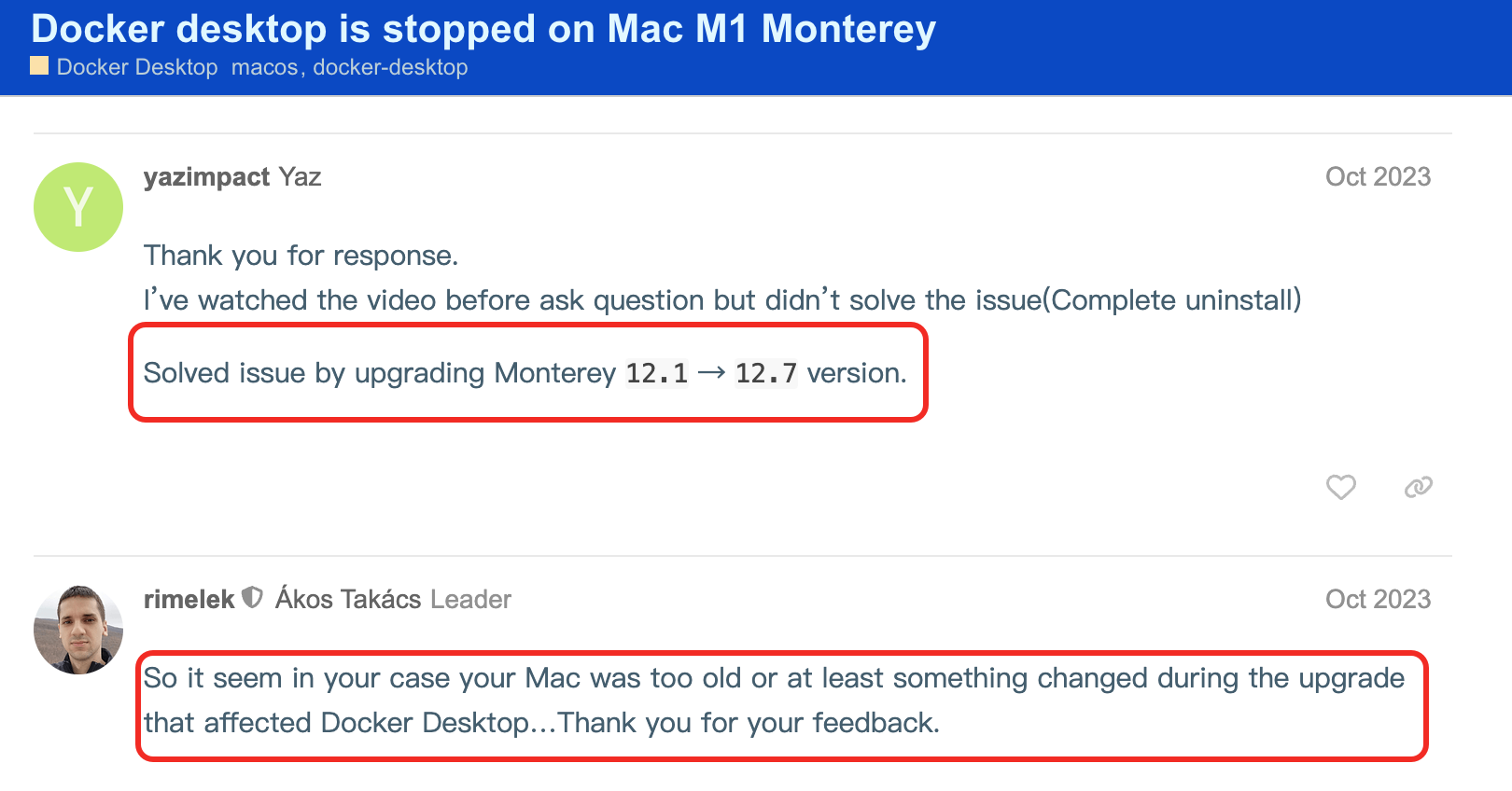
遇到的问题就是在 mac 上装好 docker,只要一启动,电脑就直接死机。白屏安装、命令行安装、换了好几个 docker 版本,无论怎么搞,全都疯狂死机。最后查了下 docker 社区,怀疑和特定的 mac os 版本有关。
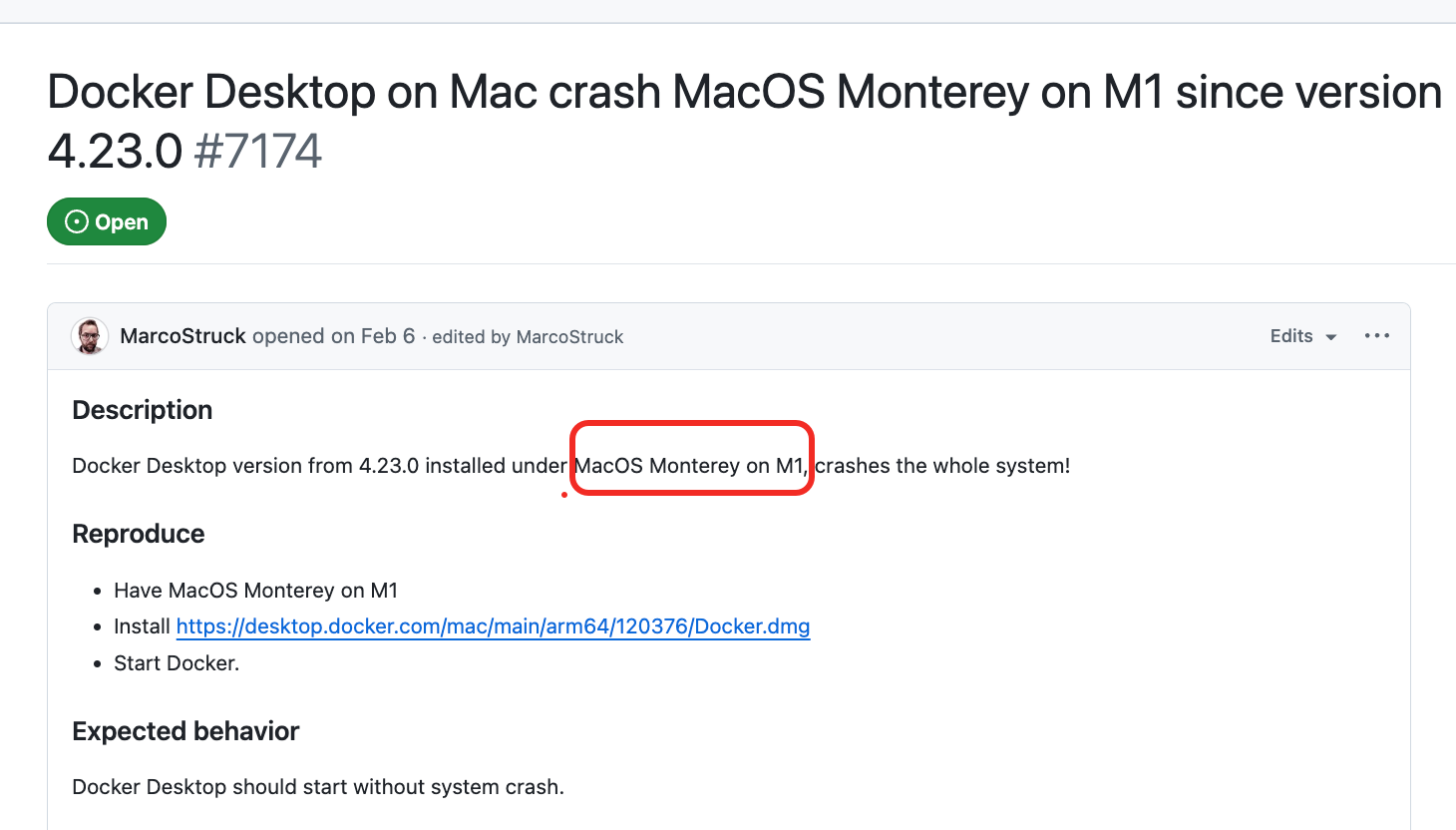
其实装 docker 的时候人家警告过一次,可惜当时看到 docker was successfully installed! 就鸣金收兵了,忽略了后面的 warning……
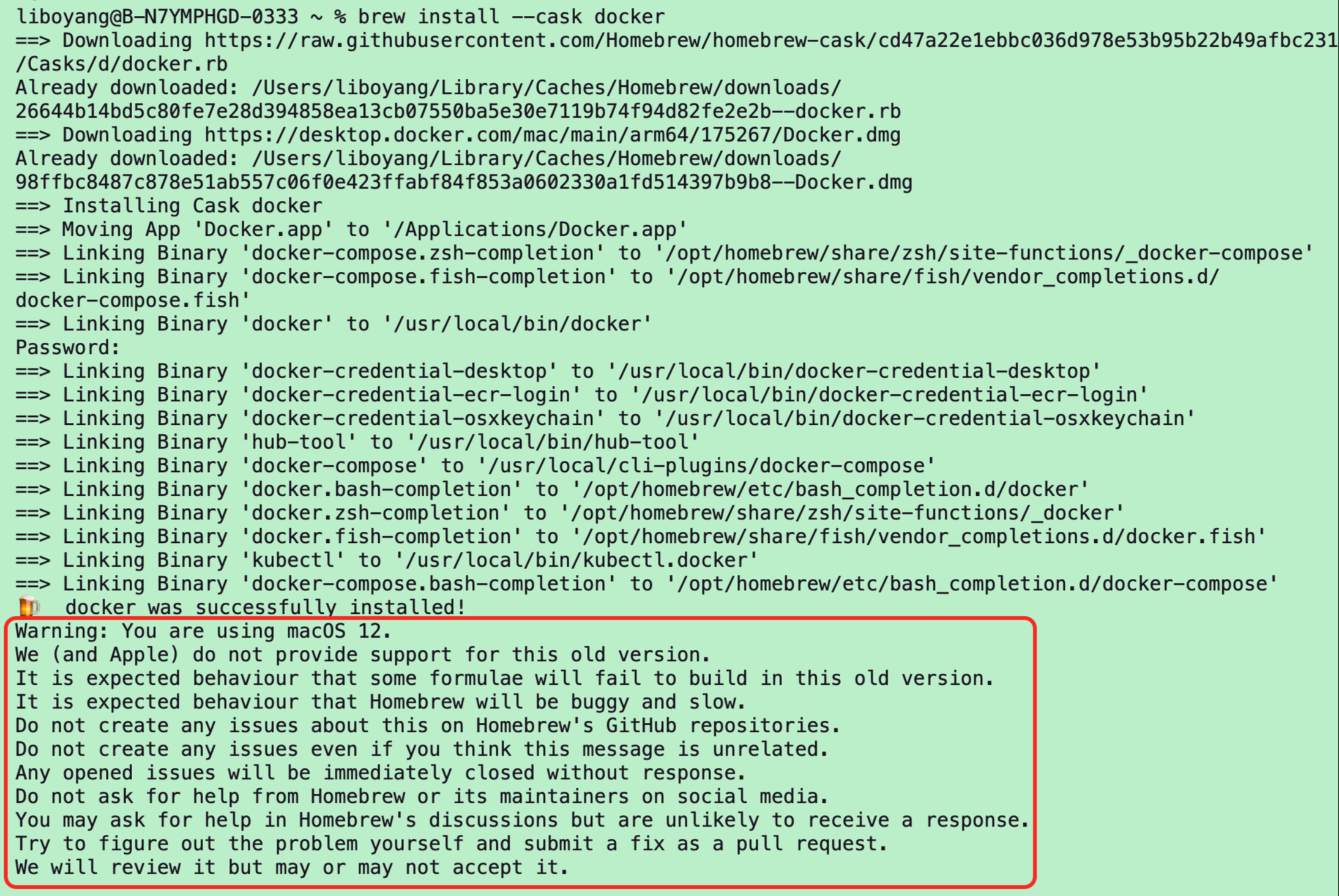
和 docker 适配存在问题的 mac os 版本好像有 12.1 ~ 12.3 这几个小版本,更低的 11.x 版本,或者更高的 13.x 及以上版本,都没有问题。我把 mac os 系统从 12.x(monterey) 升级到 15.x(sequoia)之后,问题就解决了。
不同的操作系统安装 docker 和 docker compose 的方式有所不同。我的是桌面系统,装 docker desktop 就自带了 docker 和 docker compose 命令。如果是服务器系统,需要参考 docker c7电子娱乐官网中 和 的安装指南。例如:
- centos 的安装命令如下:
# https://docs.docker.com/engine/install/centos/
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo systemctl start docker- ubuntu 的安装命令如下:
# https://docs.docker.com/engine/install/ubuntu/
# add docker's official gpg key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fssl https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a r /etc/apt/keyrings/docker.asc
# add the repository to apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$version_codename") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin特别关注
这里还有几处可能需要大家注意一下的点:
- 第一个是如果大家已经有了 oceanbase 的测试环境,就没必要再重新搭建一个新的 oceanbase 集群了,直接用就可以。
- 第二个是需要打开向量索引功能(默认关闭),可以参考。
show parameters like 'ob_vector_memory_limit_percentage'\g
*************************** 1. row ***************************
zone: zone1
svr_type: observer
svr_ip: 1.2.3.4
svr_port: 22602
name: ob_vector_memory_limit_percentage
data_type: int
value: 0
info: used to control the upper limit percentage of memory resources that the vector_index module can use. range:[0, 100)
section: tenant
scope: tenant
source: default
edit_level: dynamic_effective
default_value: 0
isdefault: 1
1 row in set (0.02 sec)alter system set ob_vector_memory_limit_percentage = 30;
show parameters like 'ob_vector_memory_limit_percentage'\g
*************************** 1. row ***************************
zone: zone1
svr_type: observer
svr_ip: 11.158.31.20
svr_port: 22602
name: ob_vector_memory_limit_percentage
data_type: int
value: 30
info: used to control the upper limit percentage of memory resources that the vector_index module can use. range:[0, 100)
section: tenant
scope: tenant
source: default
edit_level: dynamic_effective
default_value: 0
isdefault: 0
1 row in set (0.03 sec)
- 第三个是需要在 oceanbase 里创建两个不同的 database,分别用作元数据库,以及向量数据库。这里个人建议创建两个新库,没必要偷懒复用老库。
create database dify_meta_db;
create database dify_vec_db;- 第四个是如果没用 docker 启 oceanbase,而是用了个现成的测试环境,.env 文件的 host 这里就需要写下 ip 地址(docker 环境 host 直接写 oceanbase 就好了)。
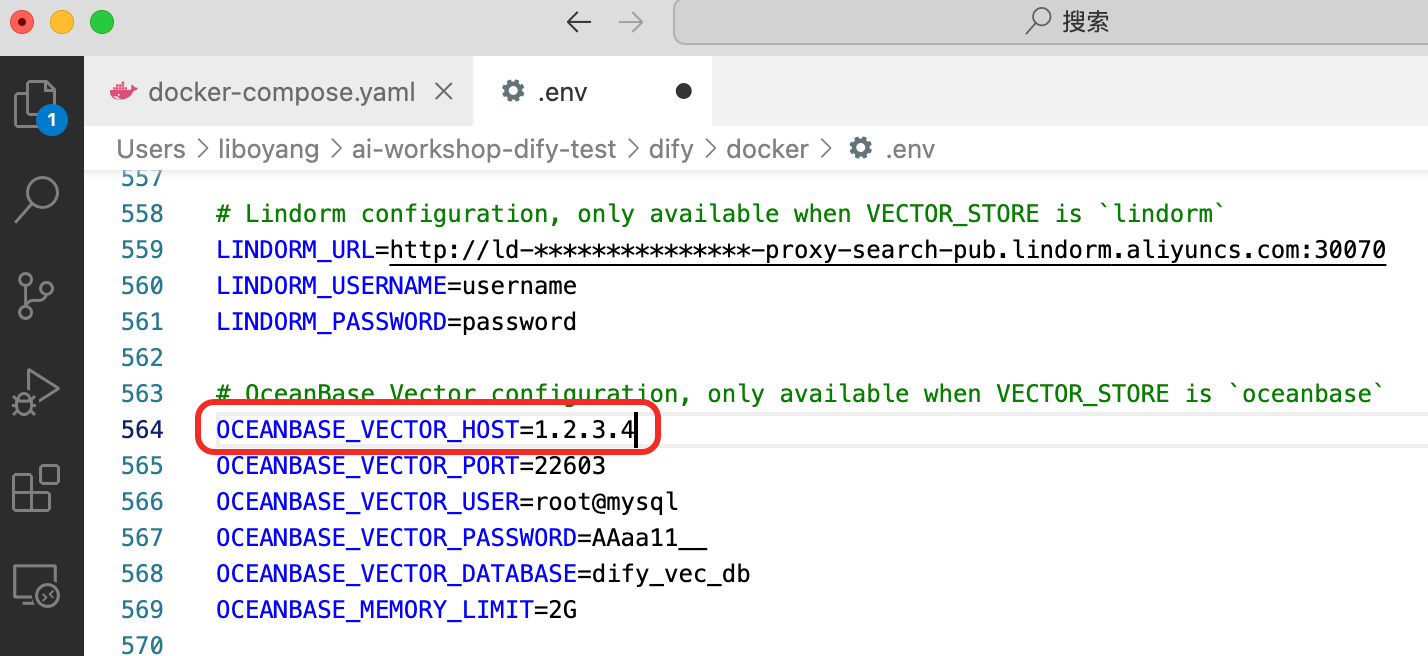
如果一开始 host 这里漏写数据 ip 地址了(或者写错了什么其他东西),在文档已上传至知识库之后,嵌入处理时会报数据库 server 链接有误的错。改完之后,重启 docker 组,再在网页里重新访问一下 localhost:80 就好了。大家在测试的时候可以先只上传一个文件,跑通流程后,再上传完整知识库。
docker compose --profile workshop down
docker compose --profile workshop up -d准备数据
这次的 dify 平台应用很多,但本着先把一件事做好的原则,咱们还是完善一下上次的答疑机器人,在工作室添加一个聊天助手的应用。
相比上回,这次 dify 的知识库文档无论是支持的格式还是来源,都更为丰富。
而且 dify 的知识库管理和在库里增删内容等操作也都十分方便。为了不显得自己只打游戏不干活,这次在知识库里,会主打学习和工作。为了避免功能回退,也添加了少量和游戏相关的内容。
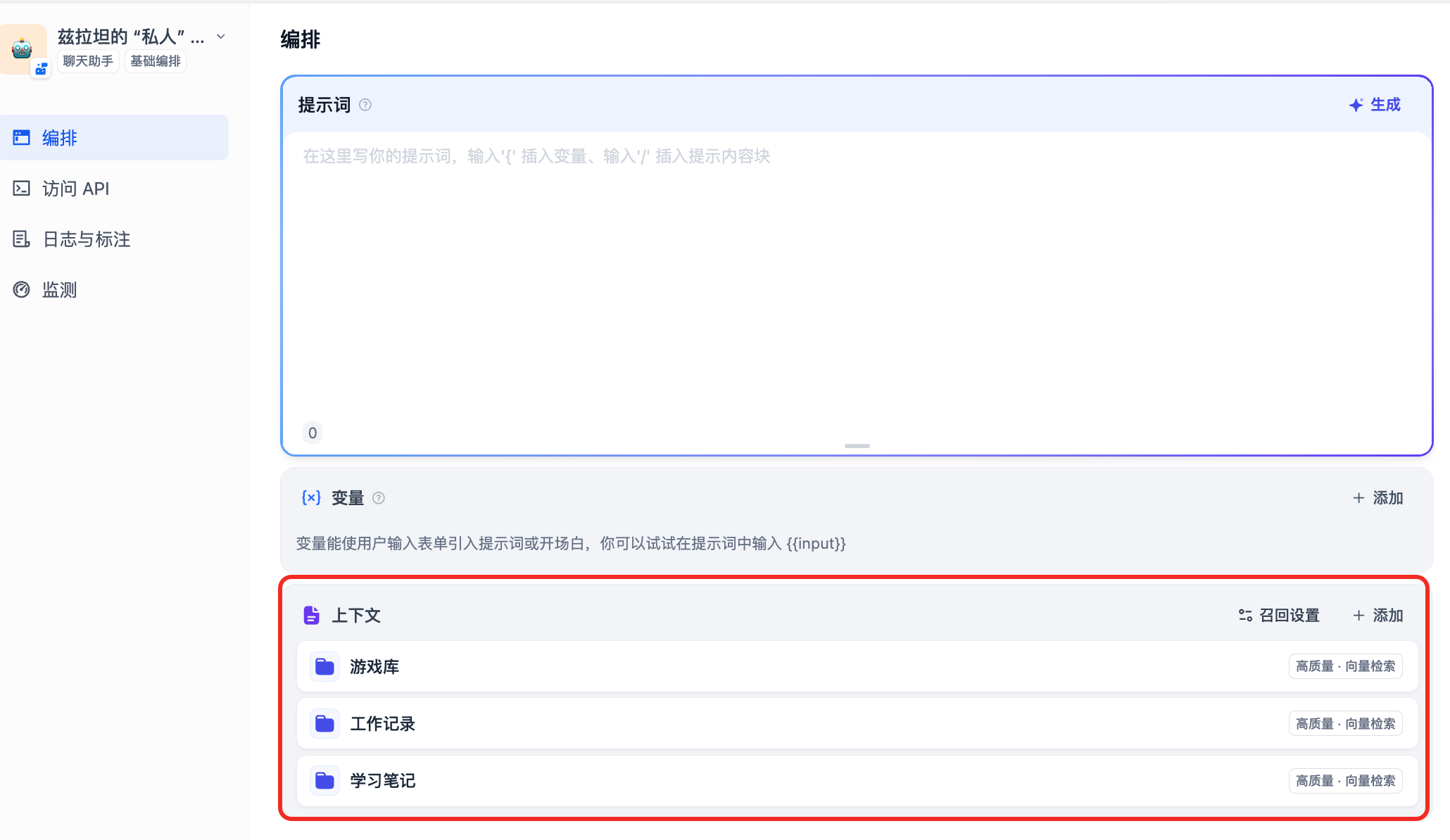
在 “私人” ai 助手里,一股脑儿把三个知识库都给加进去。
效果展示
查学习笔记:

查工作手册:
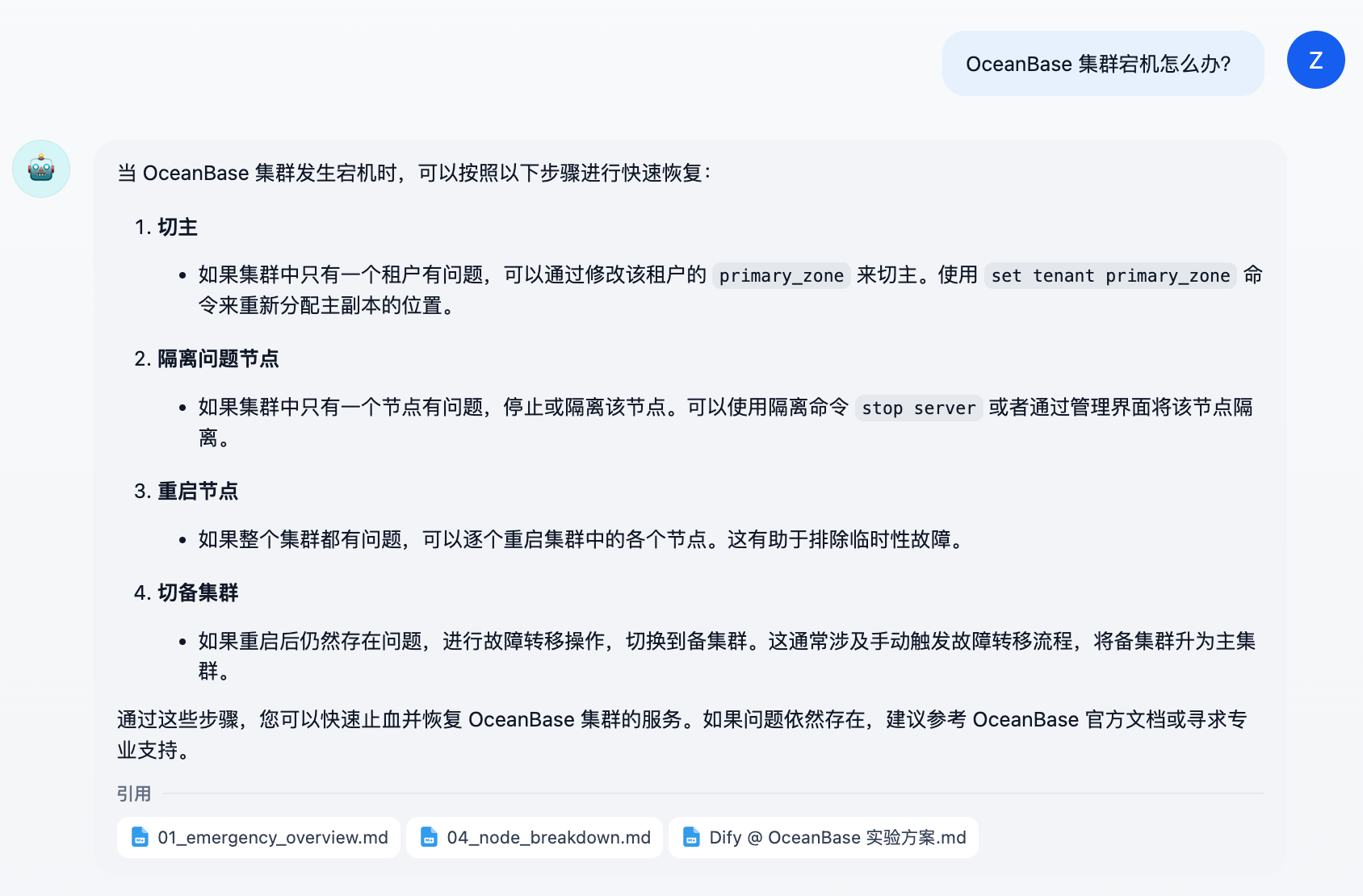
查其他内容:
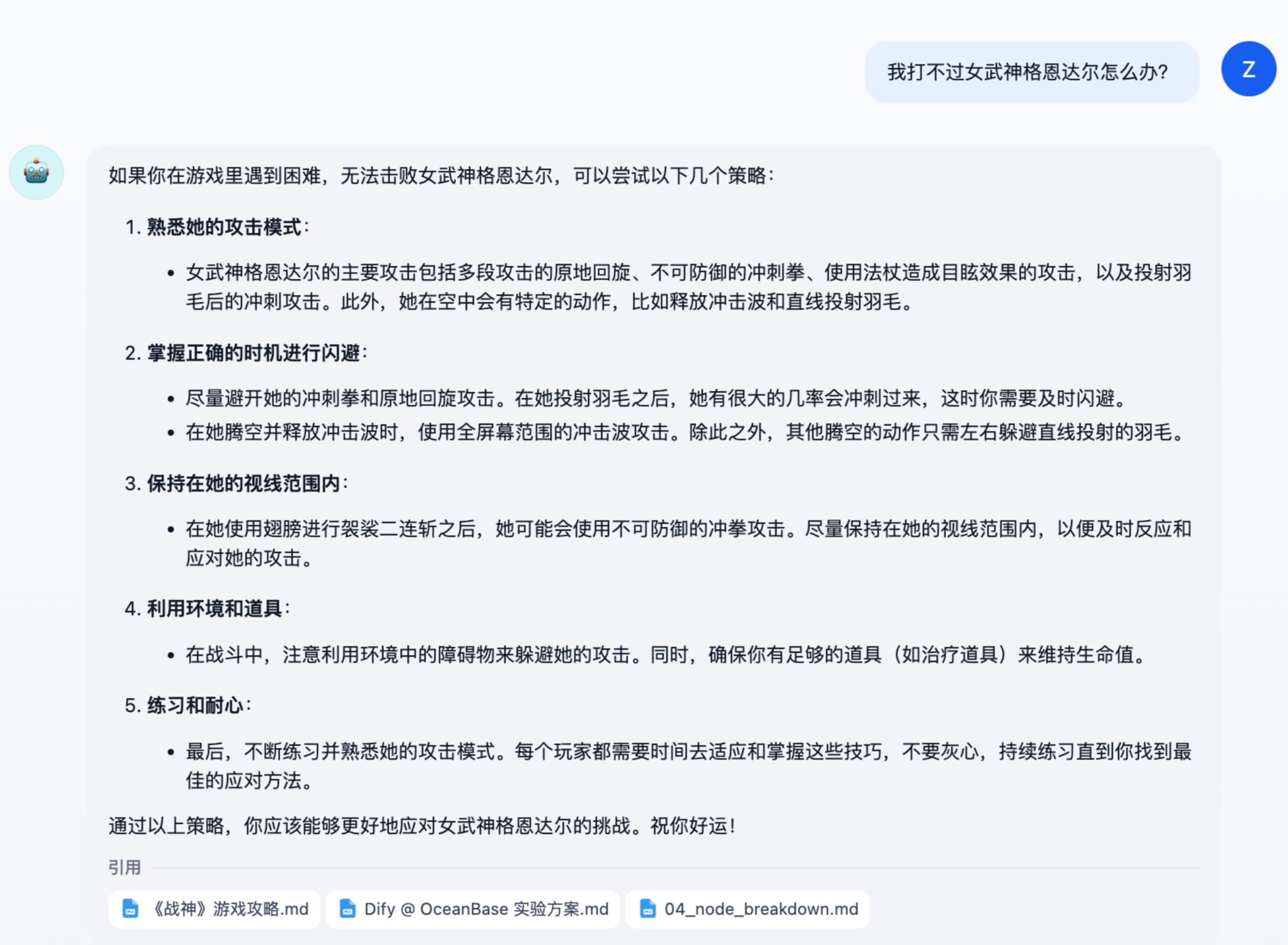
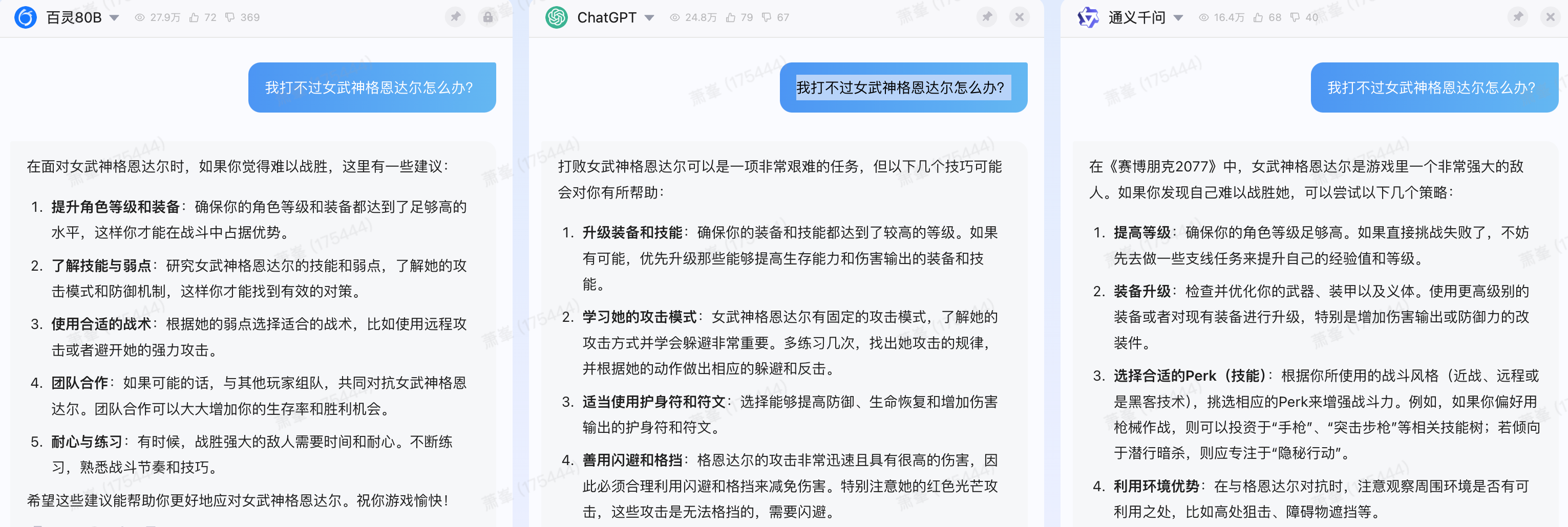
相比下面这些散养的答疑机器人,亲手喂过的真是好用太多了(下图看不清的话,可以点击放大)。
oceanbase 中对应的变化
创建知识库前,会在 oceanbase 的 dify_meta_db 库中创建一批元数据表,这里不再展示。
创建三个知识库后,oceanbase 的 dify_vec_db 中会多出三张包含向量类型的表,表中数据类型为 vector(1024) 的 vector 列就是一个超多维的向量类型,用于快速进行相似性查询。
show tables;
--------------------------------------------------------
| tables_in_dify_vec_db |
--------------------------------------------------------
| vector_index_0133ecb9_e53c_436e_81f8_d0c8a3183ecb_node |
| vector_index_2e1ddcd9_4403_4dc3_9dd6_7cfede20847a_node |
| vector_index_d1b70230_027d_4556_ac4f_9f5d12ad3f0a_node |
--------------------------------------------------------
3 rows in set (0.03 sec)
desc vector_index_0133ecb9_e53c_436e_81f8_d0c8a3183ecb_node;
---------- -------------- ------ ----- --------- -------
| field | type | null | key | default | extra |
---------- -------------- ------ ----- --------- -------
| id | varchar(36) | no | pri | null | |
| vector | vector(1024) | yes | | null | |
| text | longtext | yes | | null | |
| metadata | json | yes | | null | |
---------- -------------- ------ ----- --------- -------
4 rows in set (0.03 sec)除此以外,每张表上还能看到一个叫做 vector_index 的。在机器人回答用户提问时,会通过向量索引召回数据,在注入 prompt 之后,提交给大模型生成回答。
show create table vector_index_0133ecb9_e53c_436e_81f8_d0c8a3183ecb_node\g
*************************** 1. row ***************************
table: vector_index_0133ecb9_e53c_436e_81f8_d0c8a3183ecb_node
create table: create table `vector_index_0133ecb9_e53c_436e_81f8_d0c8a3183ecb_node` (
`id` varchar(36) not null,
`vector` vector(1024) default null,
`text` longtext default null,
`metadata` json default null,
primary key (`id`),
vector key `vector_index` (`vector`) with (distance=l2,m=16,ef_construction=256,lib=vsag,type=hnsw, ef_search=64) block_size 16384
) default charset = utf8mb4 row_format = dynamic compression = 'zstd_1.3.8'
1 row in set (0.03 sec)
what's more?
其一
看到有社区开发者发现了一种近乎 “白嫖” 的玩法,在这里分享给大家:
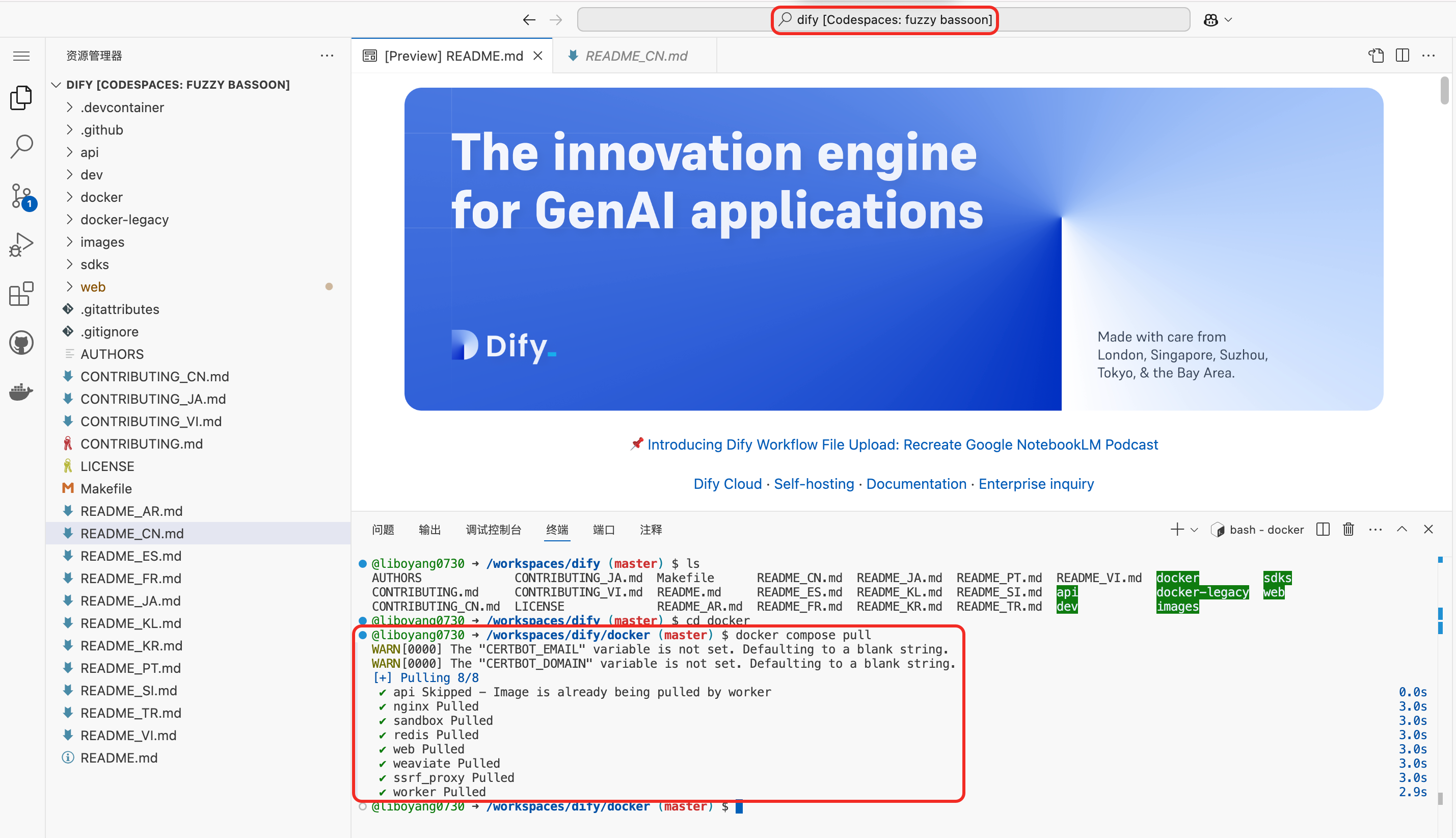
- docker 用 的免费资源,跑在 codespace 上。
- 向量数据库用 oceanbase 的免费资源,跑在 上。现在(2024.12.03) obcloud 有个 free trial 活动,可以免费用一年,强烈推荐。
其二
上面的例子是搭建 “私人” 的机器人,有了 dify x oceanbase,完全可以扩展成团队共用的机器人。
除此以外,dify 也支持把你的机器人集成到其他应用中。
未完待续
oceanbase 有了向量能力,可以支持的大模型应用场景,远不止答疑机器人这么简单。
to be continue.
参考
- ,这篇文章就是文中 “用户发文表示还不够过瘾,希望让我们能够继续打磨下这个实验项目” 的出处。
- ,欢迎大家一试。


