通过实验告诉你:增删改操作在ob v3中的写入执行流程-c7电子娱乐
之前有跟同事讨论了关于增删改在ob 3.x 中执行的过程的问题,以及执行的过程与分布式事务、两阶段提交和paxos协议的关系,感觉有人还是对上述这些关系认识不清晰,那么本人在对于官方文档和《oceanbase数据库源码解析》的学习后,说说自己的认识,同时希望有更多的人看到并纠正我说得不准确的点。
一、先写memtable还是clog?
首先引出第一个问题点,dml语句的增删改操作先写memtable还是先将clog(redo log)持久化?
可能还是有人会认为是先持久化clog,原因肯定是wal(write-ahead logging)啊。但ob对于wal的实现是“提交完成(commited)前”将redo log持久化,而不是说“数据写入内存前”就把这次操作的redo log给持久化。即使发生宕机,刚刚对memtable写入的操作丢失了也没关系,毕竟提交没有完成,副本切主后,ob可根据事务的状态来决定是进行回滚操作,还是基于redo日志回放操作来让事务继续执行。
下面看一个实验:开启事务执行sql但不提交,通过ob_admin解析clog日志和查看observer.log日志来观察ob的动作。
(1)创建一张表,此表的table_id是1100611139453782
obclient [test]> create table t1(id int not null auto_increment primary key , name varchar(20));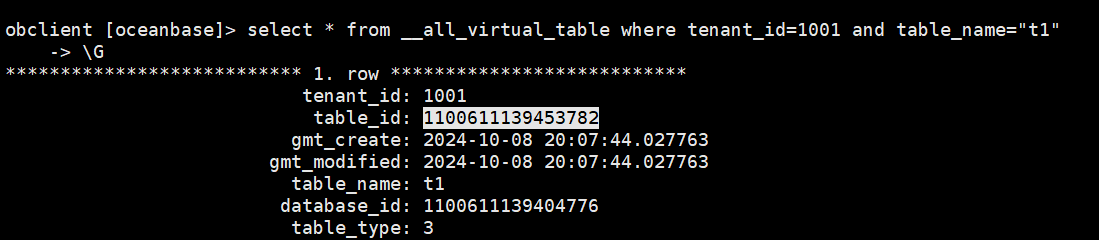
(2)插入了三条数据
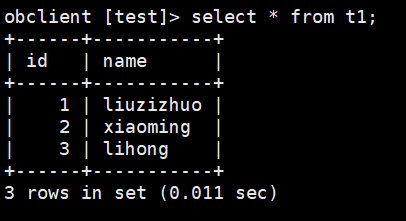
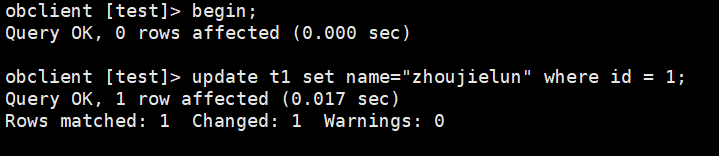
(3)更改其中一行数据,根据tid实时追踪observer.log日志,可看到此事务的事务id是“565058874603941531”,同时可看到这张表的leader是在133.145节点,而会话是在133.141节点上建立的(即scheduler是133.141节点),因此这个事务就是分布式事务。
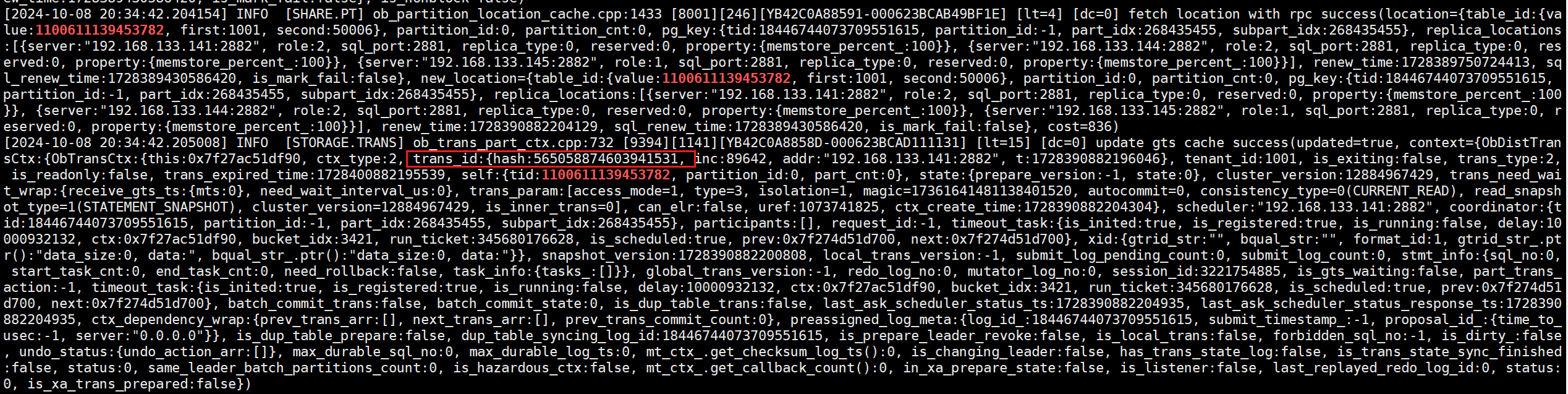
(4)根据事务的id去追踪clog文件。发现三个节点都没有此事务的相关日志,说明这个时候还没将事务的修改操作写入clog。

(5)执行commit将此事务提交,commit响应后再次通过ob_admin工具解析clog文件。
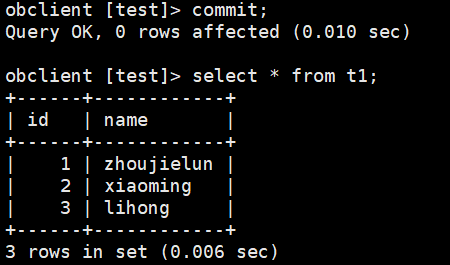
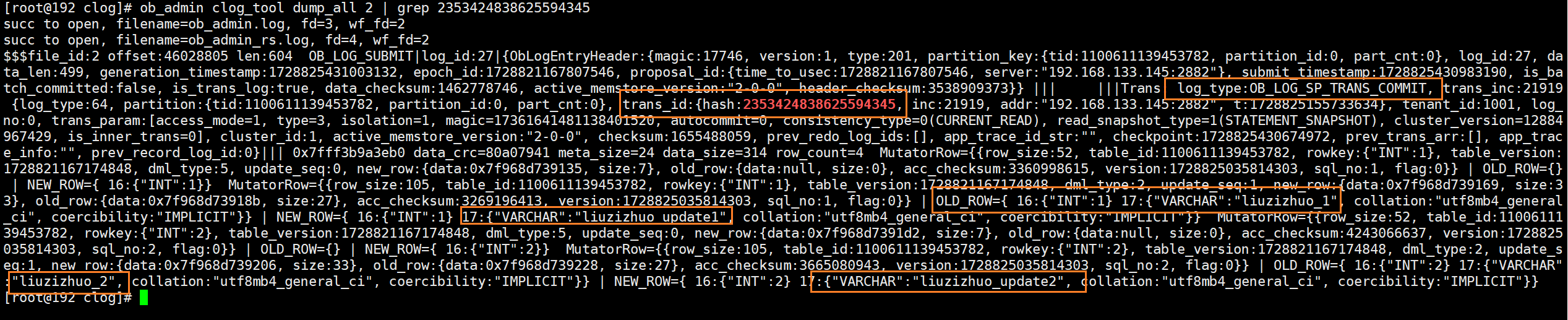
由clog的解析结果可以看到log_type为ob_log_trans_redo_with_prepare的日志中记录了旧版本数据“liuzizhuo”和新版本数据“zhoujielun”,这一条日志其实就是两阶段提交的prepare阶段的prepare日志,同时也是redo日志。后边的两个日志类型为ob_log_trans_commit和ob_log_trans_clear,它们分别为两阶段提交参与者在推高读版本号并返回响应给协调者后所持久化的commit日志和clear日志。
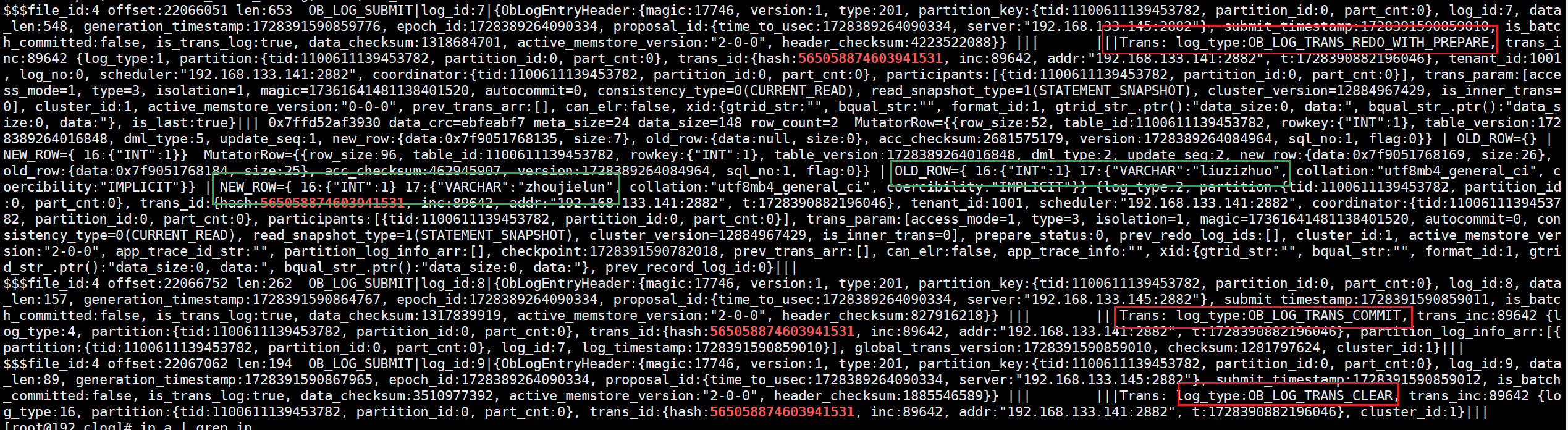
小结:其实从这个实验就能分析出增删改的写入操作,是先写memtable(即先为mvccrow追加transnode),而后再持久化redo日志。因为如果不先追加transnode,客户端是无法在当前事务下读出已修改的数据的,而此时还没有持久化相关日志,因此说是增删改是先写入memtable的。
二、clog同步与客户端commit的关系
目前了解到数据是先写入memtable的,但是clog的写入与同步是在什么情况下才触发呢,一定是commit之后才持久化和同步clog吗,答案是未必,第二章主要说明commit和clog同步的时机,接下来分事务类别并结合实验讲述。
实验之前需要知道的是,ob会逐步判断事务是本地事务还是分布式事务。本地事务又分为了本地单分区事务和本地多分区事务,本地单分区事务直接本地持久化+同步日志并完成提交即可;本地多分区事务由于在3.x版本日志流是分区维度的,所以将这种一个事务涉及单个节点中多个分区leader的本地多分区事务也算做分布式事务,ob又对这类本地多分区事务的提交做了进一步的优化。所以事务可分为三类:(1)本地单分区事务;(2)本地多分区事务(也是分布式事务);(3)传统分布式事务。
还有需要知道的是,ob的事务涉及到3个角色,而不是我们普遍认为的2个角色(协调者和参与者),除了协调者coordinator和参与者participant,还有一个叫做调度者scheduler的角色。这调度者就位于obproxy与observer建立会话的节点上的副本或者说用户会话连接到的observer节点的副本,而协调者是在commit后的两阶段提交才产生,二者被创建出的时机是不一样的。
1.本地单分区事务及相关日志类型
该实验是构造一个本地单分区事务,即事务只涉及一个分区,且会话与该分区位于同一节点。
(1)创建一张分区表,该表3个分区,分区p0 id 1-3,分区p1 id4-6,分区p2 id7-9,之后插入数据,每3行数据位于不同zone。
obclient [test]> create table t1(id int not null auto_increment primary key , name varchar(20)) partition by range(id) (partition p0 values less than(4) , partition p1 values less than(7),partition p2 values less than(10));
query ok, 0 rows affected (1.739 sec)
obclient [test]> select * from t1 order by id;
------ -------------
| id | name |
------ -------------
| 1 | liuzizhuo_1 |
| 2 | liuzizhuo_2 |
| 3 | liuzizhuo_3 |
| 4 | liuzizhuo_4 |
| 5 | liuzizhuo_5 |
| 6 | liuzizhuo_6 |
| 7 | liuzizhuo_7 |
| 8 | liuzizhuo_8 |
| 9 | liuzizhuo_9 |
------ -------------
9 rows in set (0.083 sec)
obclient [oceanbase]> select t.table_id,p.partition_id , p.svr_ip , p.role , p.zone from __all_virtual_table t join gv$partition p on p.table_id=t.table_id where t.tenant_id=1001 and p.role=1;
------------------ -------------- ----------------- ------ -------
| table_id | partition_id | svr_ip | role | zone |
------------------ -------------- ----------------- ------ -------
| 1100611139453782 | 0 | 192.168.133.145 | 1 | zone3 |
| 1100611139453782 | 1 | 192.168.133.144 | 1 | zone1 |
| 1100611139453782 | 2 | 192.168.133.141 | 1 | zone2 |
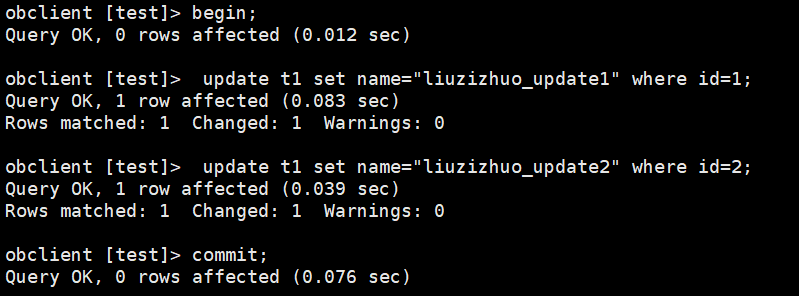
------------------ -------------- ----------------- ------ ------- (2)直接通过2881端口直连133.145节点,这样客户端与145节点建立连接,145节点即为调度者。之后执行update id=1和id=2 的操作,id为1和2的行数据属于p0分区,p0分区leader就位于145节点。
obclient [test]> begin;
query ok, 0 rows affected (0.016 sec)
obclient [test]> update t1 set name="liuzizhuo_update1" where id=1;
query ok, 1 row affected (0.009 sec)
rows matched: 1 changed: 1 warnings: 0
obclient [test]> update t1 set name="liuzizhuo_update2" where id=2;
query ok, 1 row affected (0.012 sec)
rows matched: 1 changed: 1 warnings: 0
(3)在zone3(145节点) observer日志发现事务id是2353424838625594345,可以看到调度者就在145节点,参与者也是就是p0分区自己,也在145节点。

(4)根据事务id来grep145节点的clog文件,发现本次修改的redo日志还未写入clog。

(5)之后执行commit
(6)观察除145节点外的其他节点observer.log日志, 显然可看出其他节点正在执行日志回访操作
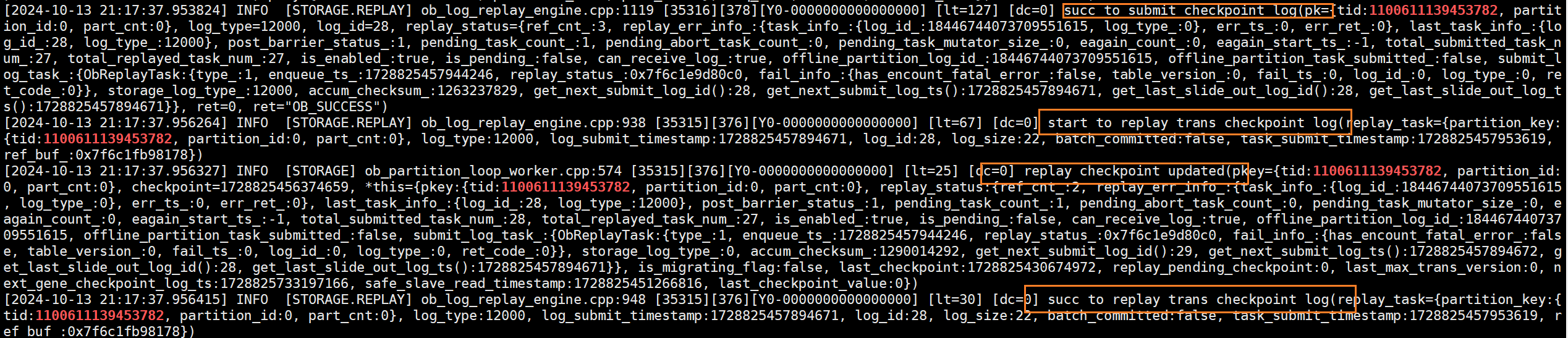
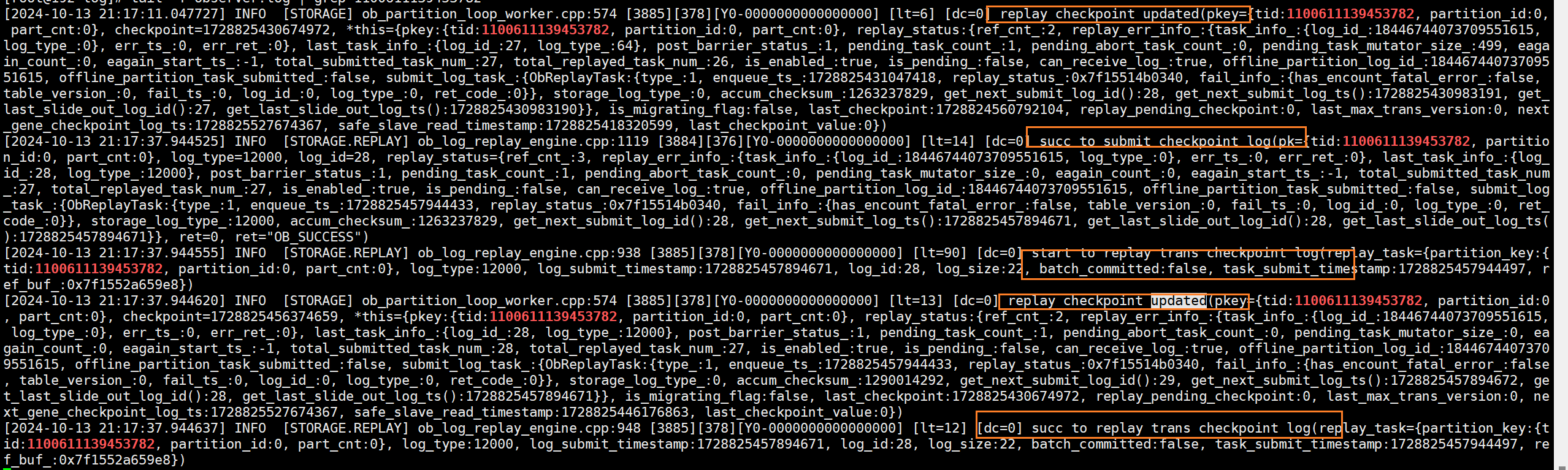
(7)再次根据事务id来grep 145节点的clog文件,发现文件中多出一条日志ob_log_sp_trans_commit,该条日志虽然是commit日志,但是其包含了本次事务对于表的修改记录。

(8)根据事务id来grep 解析后的其他节点clog文件可见ob_log_sp_trans_commit日志已经从leader副本同步至了follower副本。
(9)根据事务id追踪其他节点的observer.log日志,一直没有输出。可见其他节点并没有真正参与本次事务,只是follower副本接收到了145节点的clog日志。

小结:本地单分区事务其实就是个一阶段提交,执行commit后,事务只提交了一次ob_log_sp_trans_commit并写入本地clog文件中,该条日志中会包含本次事务所做的增删改操作的信息。之后分区leader副本所对应的clog滑动窗口将日志同步至folloer副本,follower副本的滑动窗口接收日志并交给回放引擎进行回放,回放至memtable。
2.分布式事务及相关日志类型
- 本实验是:在一个事务内将4个分区的12行数据全部修改,以构造一个分布式事务,并观察ob的行为与clog写入情况。
(1)重新创建数据表t1并灌入数据,副本p0(行id 1~3)数据在zone2(141节点),副本p1(行id 4~6)数据在zone3(145节点),副本p2(行id 7~9)数据在zone1(144节点),副本p3(行id 10~12)数据在zone2(145节点)。
obclient [test]> select * from t1;
------ --------------
| id | name |
------ --------------
| 1 | liuzizhuo_1 |
| 2 | liuzizhuo_2 |
| 3 | liuzizhuo_3 |
| 4 | liuzizhuo_4 |
| 5 | liuzizhuo_5 |
| 6 | liuzizhuo_6 |
| 7 | liuzizhuo_7 |
| 8 | liuzizhuo_8 |
| 9 | liuzizhuo_9 |
| 10 | liuzizhuo_10 |
| 11 | liuzizhuo_11 |
| 12 | liuzizhuo_12 |
------ --------------
12 rows in set (0.732 sec)
obclient [oceanbase]> select t.table_id,p.partition_id , p.svr_ip , p.role , p.zone from __all_virtual_table t join gv$partition p on p.table_id=t.table_id where t.tenant_id=1001 and p.role=1;
------------------ -------------- ----------------- ------ -------
| table_id | partition_id | svr_ip | role | zone |
------------------ -------------- ----------------- ------ -------
| 1100611139453784 | 0 | 192.168.133.141 | 1 | zone2 |
| 1100611139453784 | 1 | 192.168.133.145 | 1 | zone3 |
| 1100611139453784 | 2 | 192.168.133.144 | 1 | zone1 |
| 1100611139453784 | 3 | 192.168.133.145 | 1 | zone3 |
------------------ -------------- ----------------- ------ -------
(2)通过访问144节点2881端口来开启事务,事务id为2973974247506826778
obclient [oceanbase]> select trans_id,* from __all_virtual_processlist where tenant='lzz_test';
--------------------- ------------ ------ ---------- ----------------------- ------ --------- -------- ------ ------- ------ ----------------- ---------- ---------- -------------- --------------- ----------------- ----------- --------------------- ----------- ------------ ----------
| trans_id | id | user | tenant | host | db | command | sql_id | time | state | info | svr_ip | svr_port | sql_port | proxy_sessid | master_sessid | user_client_ip | user_host | trans_id | thread_id | ssl_cipher | trace_id |
--------------------- ------------ ------ ---------- ----------------------- ------ --------- -------- ------ ------- ------ ----------------- ---------- ---------- -------------- --------------- ----------------- ----------- --------------------- ----------- ------------ ----------
| 2973974247506826778 | 3221570638 | root | lzz_test | 192.168.133.143:58924 | test | sleep | | 3 | sleep | null | 192.168.133.144 | 2882 | 2881 | null | null | 192.168.133.143 | % | 2973974247506826778 | 0 | null | null |
--------------------- ------------ ------ ---------- ----------------------- ------ --------- -------- ------ ------- ------ ----------------- ---------- ---------- -------------- --------------- ----------------- ----------- --------------------- ----------- ------------ ----------
(3)并执行update语句,分成两条update去执行,是为了让第一条update语句的执行就能够让我们指定该事务的协调者(即协调者是p0分区leader)。update后暂时不commit;
obclient [test]> begin;
query ok, 0 rows affected (0.001 sec)
obclient [test]> update t1 set name='liuzizhuo_1-3' where id >= 1 and id <=3;
query ok, 3 rows affected (0.004 sec)
rows matched: 3 changed: 3 warnings: 0
obclient [test]> update t1 set name='liuzizhuo_4-12' where id >= 4 and id <=12;
query ok, 9 rows affected (0.007 sec)
rows matched: 9 changed: 9 warnings: 0
(4)这时还没有commit,根据事务id搜索解析后的clog,发现这时修改的数据记录还没有写入clog。

(5)执行commit。commit后,三个节点中任意一个节点的observer日志当中可以看到大量的关于回放redo的日志,并且能够看到redo回放开始的动作以及回放成功的动作。
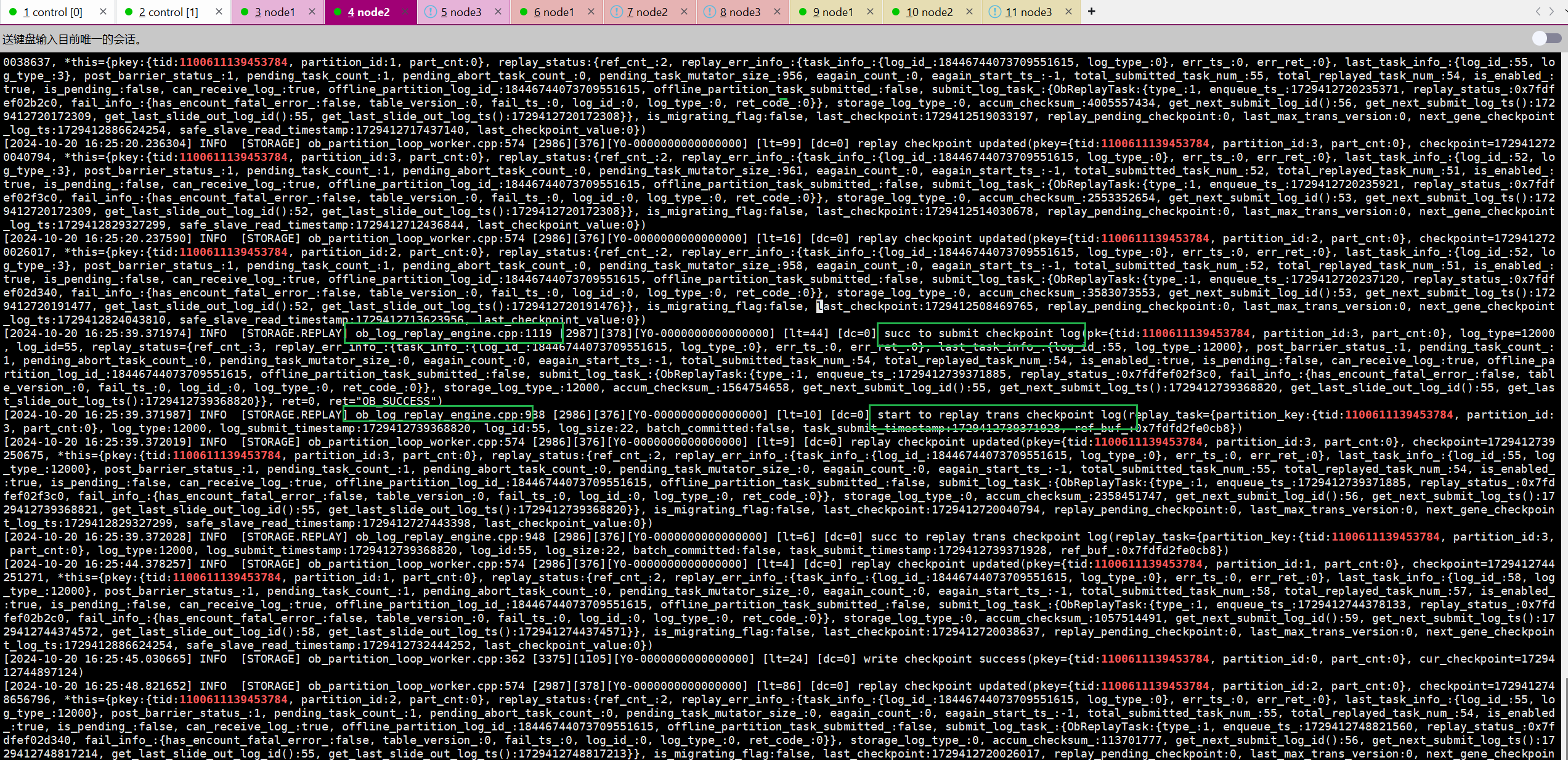
(6)再次根据事务id解析clog日志,可以看到日志类型为ob_log_trans_redo_with_prepare的日志,这一类型的日志是分布式事务的 prepare 日志,同时包含了本次事务的redo日志。从中还能够看到调度者scheduler为会话建立的节点144,协调者为141节点的副本,可见调度者和协调者不是同一节点,协调者则是第一个参与写操作的参与者,即分区p0(141节点)。
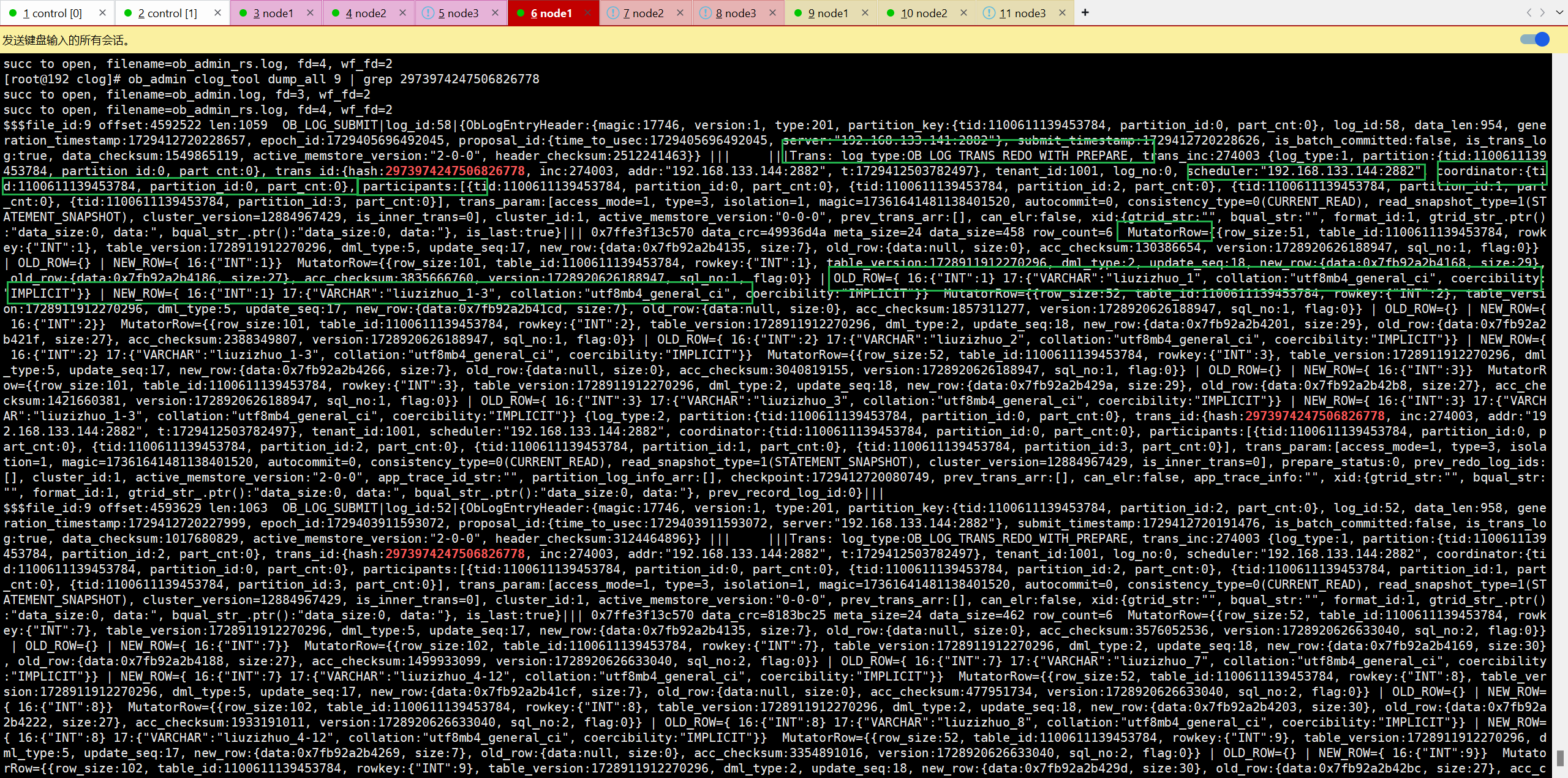
我们能够在每个节点的clog日志中都能发现4条ob_log_trans_redo_with_prepare,即一个分区对应了一条ob_log_trans_redo_with_prepare日志。同时发现相同epoch id的日志在每个节点都持久化了一份,每份日志内容都相同(除了物理地址和offset不同以外)。
除了prepare with redo日志外,还有ob_log_trans_commit和ob_log_trans_clear,这就是ob两阶段提交各个参与者在pre-commit ok后所持久化的commit日志和clear日志。
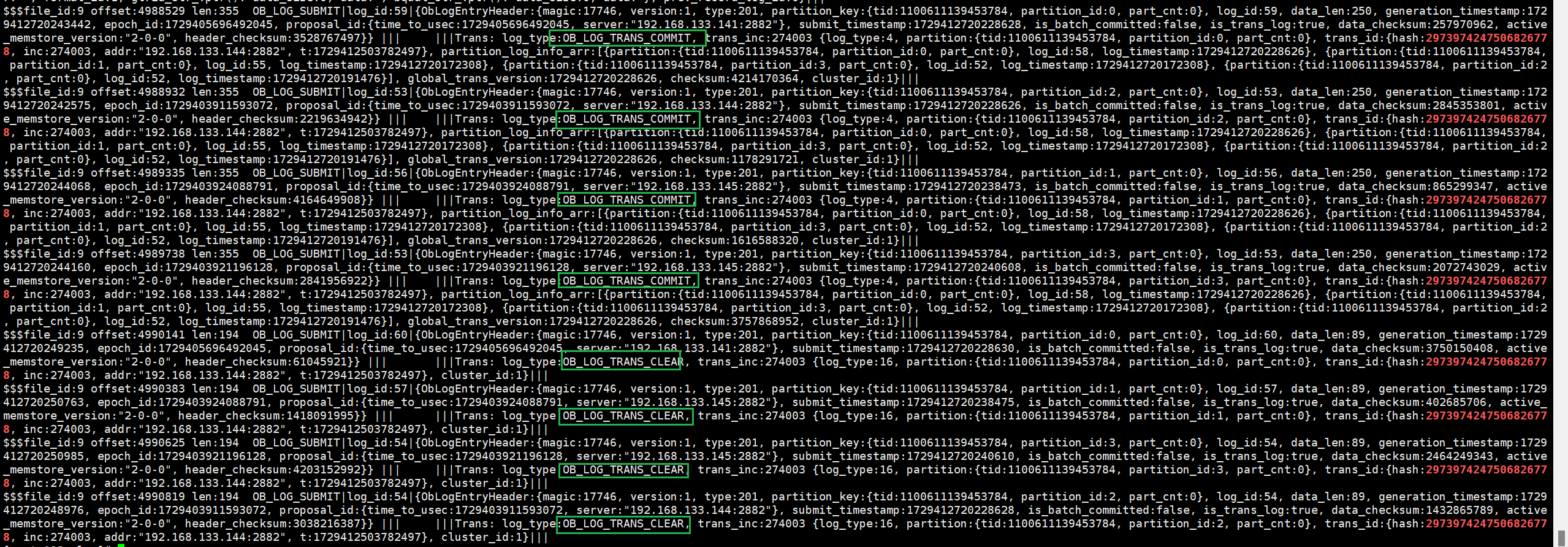
小结:
1、分布式事务的整个全局事务开始于调度者节点,由调度者将子任务发送至各参与者leader节点,各个参与者接受子任务并执行局部事务,之后各个参与者节点先写memtable同时维护各自的事务上下文。
2、客户端执行commit后,第一个参与写操作的参与者被任命为协调者,协调者向所有参与者leader发送prepare请求,各个参与者将事务内存数据和事务上下文持久化为本地日志ob_log_trans_redo_with_prepare,该日志融合prepare日志和redo日志,以及生成本地提交版本号。参与者leader本地持久化redo with prepare日志并同步至对应follower节点,多数派持久化该日志成功后告知协调者,同时follwer节点会对日志进行回放至memtable的动作。上边提到的日志同步才会涉及到paxos accept,以达到对日志共识的目的、保证事务原子性,不要把paxos和两阶段提交搞混,这是两个不同维度的事情。
3、协调者取所有参与者中的最大prepare version作为事务的commit version再推给参与者并通知参与者进入pre-commit阶段,在pre-commit阶段推高各个参与者的max commit version,当所有参与者完成pre-commit并通知协调者后,协调者再响应客户端。
4、最后两阶段提交的commit阶段,首先参与者持久化commit日志ob_log_trans_commit并同步至对应的follower副本,协调者收到所有参与者持久化并同步完日志的消息后,将事务状态更新为clear状态,再通知所有参与者清空自己的上下文,同样需要持久化并同步clear日志ob_log_trans_clear。
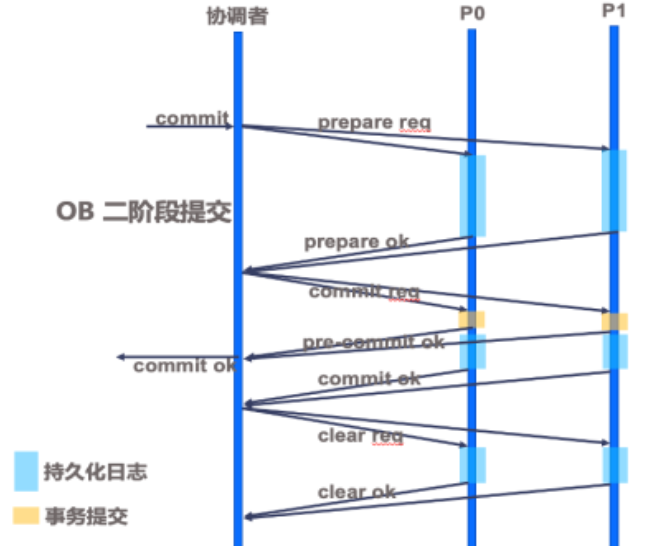
三、clog同步不只和commit有关系
其实clog同步不光和commit有关系,还同时与转储、事务内存数据大小,接下来看两个实验。
1.转储
(1)继续用之前实验使用的t1表,不过因为本人虚拟机重启了,分区leader也变了,不过不影响后边实验。
obclient [test]> select * from t1;
------ ----------------
| id | name |
------ ----------------
| 4 | liuzizhuo_4-12 |
| 5 | liuzizhuo_4-12 |
| 6 | liuzizhuo_4-12 |
| 7 | liuzizhuo_4-12 |
| 8 | liuzizhuo_4-12 |
| 9 | liuzizhuo_4-12 |
| 10 | liuzizhuo_4-12 |
| 11 | liuzizhuo_4-12 |
| 12 | liuzizhuo_4-12 |
| 1 | liuzizhuo_1-3 |
| 2 | liuzizhuo_1-3 |
| 3 | liuzizhuo_1-3 |
------ ----------------
12 rows in set (0.083 sec)
obclient [oceanbase]> select t.table_id,p.partition_id , p.svr_ip , p.role , p.zone from __all_virtual_table t join gv$partition p on p.table_id=t.table_id where t.tenant_id=1001 and p.role=1;
------------------ -------------- ----------------- ------ -------
| table_id | partition_id | svr_ip | role | zone |
------------------ -------------- ----------------- ------ -------
| 1100611139453784 | 0 | 192.168.133.141 | 1 | zone2 |
| 1100611139453784 | 1 | 192.168.133.145 | 1 | zone3 |
| 1100611139453784 | 2 | 192.168.133.145 | 1 | zone3 |
| 1100611139453784 | 3 | 192.168.133.144 | 1 | zone1 |
------------------ -------------- ----------------- ------ -------
4 rows in set (1.659 sec)(2)开启一个事务,事务id为11474318964278020578
obclient [oceanbase]> select trans_id,* from __all_virtual_processlist where tenant='lzz_test';
---------------------- ------------ ------ ---------- ----------------------- ------ --------- -------- ------ ------- ------ ----------------- ---------- ---------- -------------- --------------- ----------------- ----------- ---------------------- ----------- ------------ ----------
| trans_id | id | user | tenant | host | db | command | sql_id | time | state | info | svr_ip | svr_port | sql_port | proxy_sessid | master_sessid | user_client_ip | user_host | trans_id | thread_id | ssl_cipher | trace_id |
---------------------- ------------ ------ ---------- ----------------------- ------ --------- -------- ------ ------- ------ ----------------- ---------- ---------- -------------- --------------- ----------------- ----------- ---------------------- ----------- ------------ ----------
| 11474318964278020578 | 3222061870 | root | lzz_test | 192.168.133.143:54604 | test | sleep | | 2 | sleep | null | 192.168.133.145 | 2882 | 2881 | null | null | 192.168.133.143 | % | 11474318964278020578 | 0 | null | null |
---------------------- ------------ ------ ---------- ----------------------- ------ --------- -------- ------ ------- ------ ----------------- ---------- ---------- -------------- --------------- ----------------- ----------- ---------------------- ----------- ------------ ----------
1 row in set (0.652 sec)(3)执行update语句,将所有的行数据进行修改。
obclient [test]> begin;
query ok, 0 rows affected (0.011 sec)
obclient [test]> update t1 set name = "liuzizhuo_all" where id >= 1 and id <= 12;
query ok, 12 rows affected (0.313 sec)
rows matched: 12 changed: 12 warnings: 0
(4)解析clog文件并发现无此事务日志,符合预期。

(5)sys租户下触发转储
obclient [oceanbase]> alter system minor freeze;
query ok, 0 rows affected (13.486 sec)
obclient [oceanbase]> select * from __all_server_event_history where event like "%minor%" order by gmt_create desc;
---------------------------- ----------------- ---------- -------- ------------------------- ----------- -------- ------- -------- ------- -------- ------- -------- ------- -------- ------- -------- ------------
| gmt_create | svr_ip | svr_port | module | event | name1 | value1 | name2 | value2 | name3 | value3 | name4 | value4 | name5 | value5 | name6 | value6 | extra_info |
---------------------------- ----------------- ---------- -------- ------------------------- ----------- -------- ------- -------- ------- -------- ------- -------- ------- -------- ------- -------- ------------
| 2024-10-21 21:48:53.814567 | 192.168.133.141 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | null | | | | | | | | | |
| 2024-10-21 21:48:52.176701 | 192.168.133.144 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | null | | | | | | | | | |
| 2024-10-21 21:48:50.272395 | 192.168.133.145 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | null | | | | | | | | | |
| 2024-10-21 21:48:45.184680 | 192.168.133.145 | 2882 | freeze | do minor freeze | tenant_id | 0 | | null | | | | | | | | | |
| 2024-10-21 21:48:45.175198 | 192.168.133.141 | 2882 | freeze | do minor freeze | tenant_id | 0 | | null | | | | | | | | | |
| 2024-10-21 21:48:45.173701 | 192.168.133.144 | 2882 | freeze | do minor freeze | tenant_id | 0 | | null | | | | | | | | | |
(6)observer日志打印关于标记脏事务的动作以及关于回放mutator日志的动作。
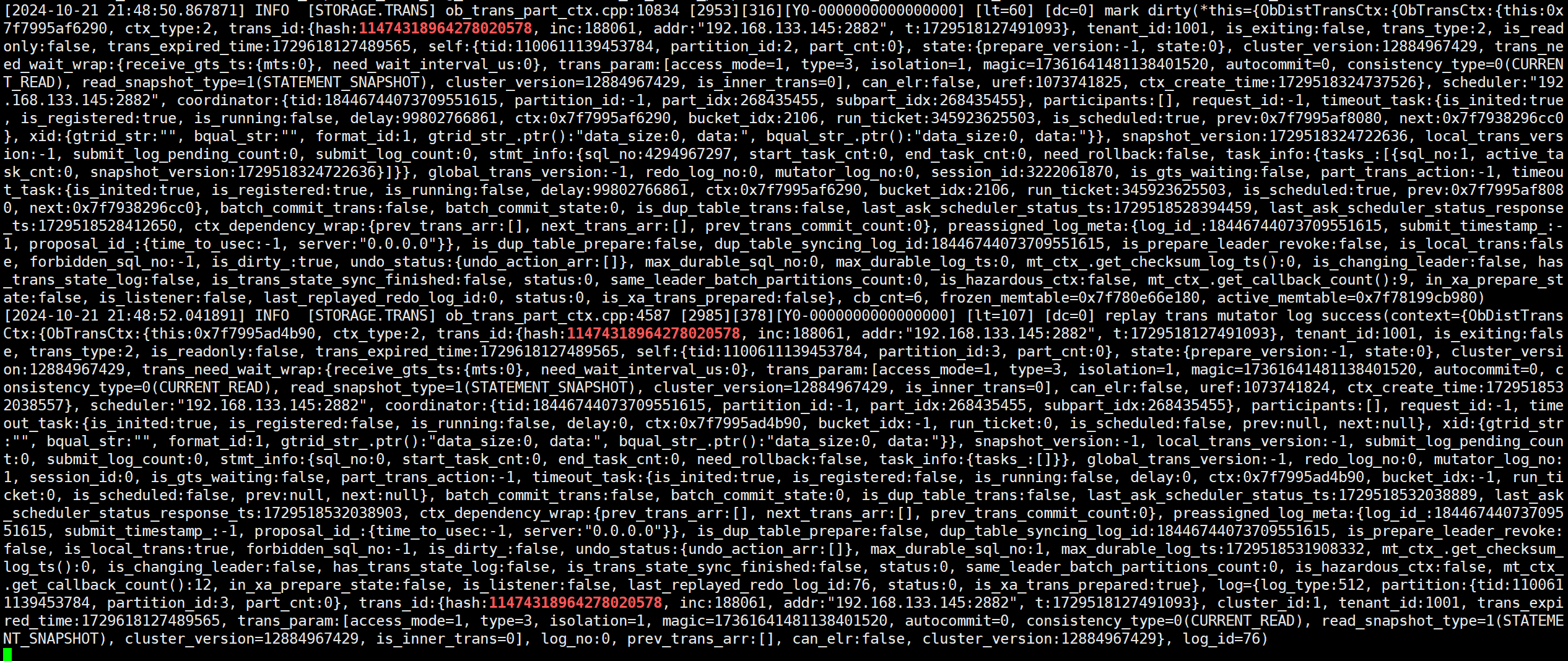
(7)能够看到脏事务的存在(未提交但是发生转储的事务)以及相关的表分区。
obclient [oceanbase]> select * from gv$ob_trans_table_status where tenant_id=1001 and table_id=1100611139453784;
----------------- ---------- ----------- ------------------ -------------- ------------------ -----------
| svr_ip | svr_port | tenant_id | table_id | partition_id | end_log_id | trans_cnt |
----------------- ---------- ----------- ------------------ -------------- ------------------ -----------
| 192.168.133.141 | 2882 | 1001 | 1100611139453784 | 0 | 1729518524952924 | 2 |
| 192.168.133.141 | 2882 | 1001 | 1100611139453784 | 1 | 1729518526330103 | 0 |
| 192.168.133.141 | 2882 | 1001 | 1100611139453784 | 3 | 1729518530763423 | 1 |
| 192.168.133.141 | 2882 | 1001 | 1100611139453784 | 2 | 1729518531392604 | 1 |
| 192.168.133.144 | 2882 | 1001 | 1100611139453784 | 0 | 1729518524952924 | 1 |
| 192.168.133.144 | 2882 | 1001 | 1100611139453784 | 1 | 1729518527568311 | 1 |
| 192.168.133.144 | 2882 | 1001 | 1100611139453784 | 3 | 1729518531124047 | 2 |
| 192.168.133.144 | 2882 | 1001 | 1100611139453784 | 2 | 1729518531501824 | 1 |
| 192.168.133.145 | 2882 | 1001 | 1100611139453784 | 0 | 1729518524952924 | 1 |
| 192.168.133.145 | 2882 | 1001 | 1100611139453784 | 1 | 1729518526540497 | 2 |
| 192.168.133.145 | 2882 | 1001 | 1100611139453784 | 3 | 1729518529224612 | 1 |
| 192.168.133.145 | 2882 | 1001 | 1100611139453784 | 2 | 1729518528624873 | 2 |
----------------- ---------- ----------- ------------------ -------------- ------------------ -----------
12 rows in set (0.785 sec)
(8)在还未commit期间,根据事务id解析clog,发现很多类型为ob_log_mutaor的日志,该类日志记录了未commit期间所持久化并同步的redo,第(6)步看到的回放动作也是在回放这些redo记录。

(9)commit提交事务后再次解析clog文件,发现clog中写入了ob_log_trans_prepare,该类型日志是两阶段提交的prepare日志。这时候发现commit后写入的日志并不是此前看到的ob_log_trans_redo_with_prepare,这是因为在转储后已经持久化并同步了所有的数据变化,且在转储后没有再变更数据,所以只记录了prepare日志。在prepare日志后,也能够看到此前遇到的ob_log_trans_commit和ob_log_trans_clear日志。

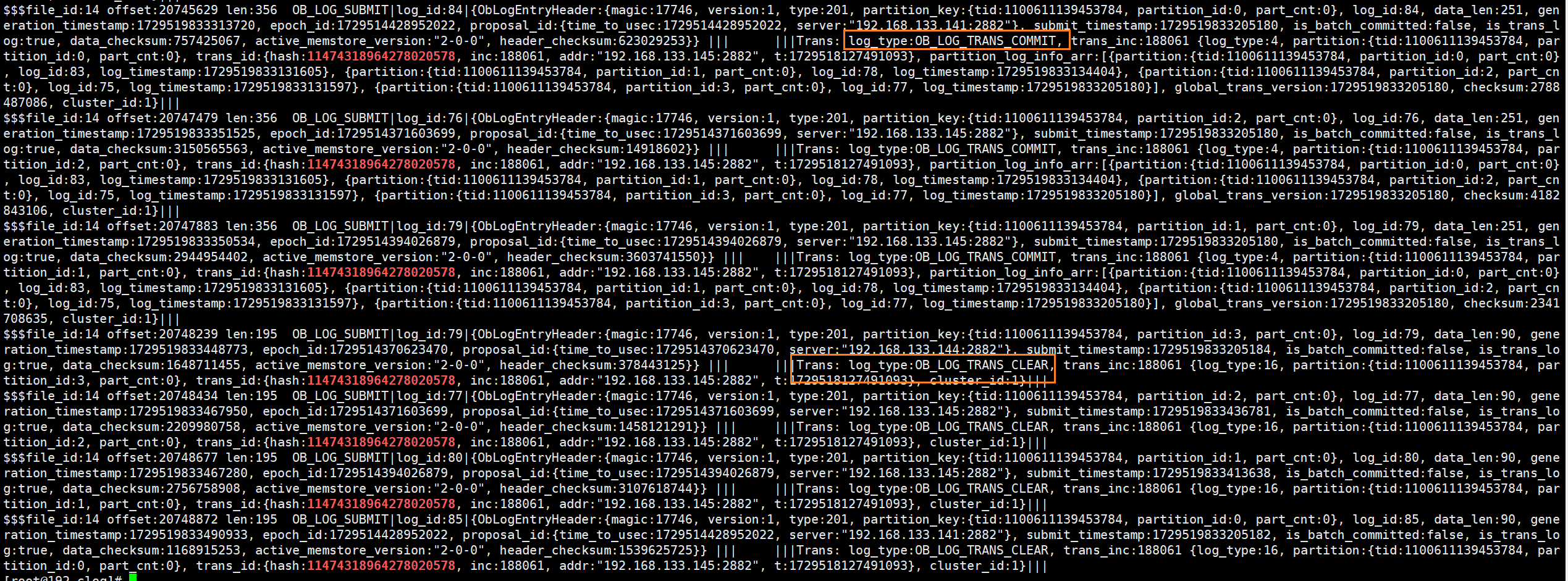
小结:在事务未结束、行数据仍在变化期间,memstore中的增量数据持续增加,直至触发冻结转储,转储会触发ob将未提交的数据变化持久化为ob_log_mutaor类型日志,并将该日志同步至follower节点的clog模块进行持久化与回放。
2.即时写日志
(1)创建一张新的分区表t2并灌入30行数据,该表一共3个分区。
obclient [test]> create table t2 (id int not null auto_increment primary key , name varchar(20),addr varchar(20)) partition by hash(id) partitions 3;
query ok, 0 rows affected (3.069 sec)
obclient [test]> select * from t2;
------ ------------- ---------
| id | name | addr |
------ ------------- ---------
| 1 | liuzizhuo1 | beijing |
| 2 | liuzizhuo2 | beijing |
. . .
. . .
. . .
| 29 | liuzizhuo29 | beijing |
| 30 | liuzizhuo30 | beijing |
------ ------------- ---------
30 rows in set (0.292 sec)
obclient [oceanbase]> select t.table_id,p.partition_id , p.svr_ip , p.role , p.zone from __all_virtual_table t join gv$partition p on p.table_id=t.table_id where t.tenant_id=1001 and p.role=1 order by table_id desc;
------------------ -------------- ----------------- ------ -------
| table_id | partition_id | svr_ip | role | zone |
------------------ -------------- ----------------- ------ -------
| 1100611139453791 | 2 | 192.168.133.145 | 1 | zone3 |
| 1100611139453791 | 1 | 192.168.133.141 | 1 | zone2 |
| 1100611139453791 | 0 | 192.168.133.144 | 1 | zone1 |
(2)begin开启事务后,事务id为14974148697483243382
obclient [oceanbase]> select trans_id,* from __all_virtual_processlist where tenant='lzz_test';
---------------------- ------------ ------ ---------- ----------------------- ------ --------- -------- ------ ------- ------ ----------------- ---------- ---------- -------------- --------------- ----------------- ----------- ---------------------- ----------- ------------ ----------
| trans_id | id | user | tenant | host | db | command | sql_id | time | state | info | svr_ip | svr_port | sql_port | proxy_sessid | master_sessid | user_client_ip | user_host | trans_id | thread_id | ssl_cipher | trace_id |
---------------------- ------------ ------ ---------- ----------------------- ------ --------- -------- ------ ------- ------ ----------------- ---------- ---------- -------------- --------------- ----------------- ----------- ---------------------- ----------- ------------ ----------
| 14974148697483243382 | 3221657595 | root | lzz_test | 192.168.133.143:45494 | test | sleep | | 13 | sleep | null | 192.168.133.144 | 2882 | 2881 | null | null | 192.168.133.143 | % | 14974148697483243382 | 0 | null | null |
---------------------- ------------ ------ ---------- ----------------------- ------ --------- -------- ------ ------- ------ ----------------- ---------- ---------- -------------- --------------- ----------------- ----------- ---------------------- ----------- ------(3)并逐步通过insert into select语句对表t2插入数据。

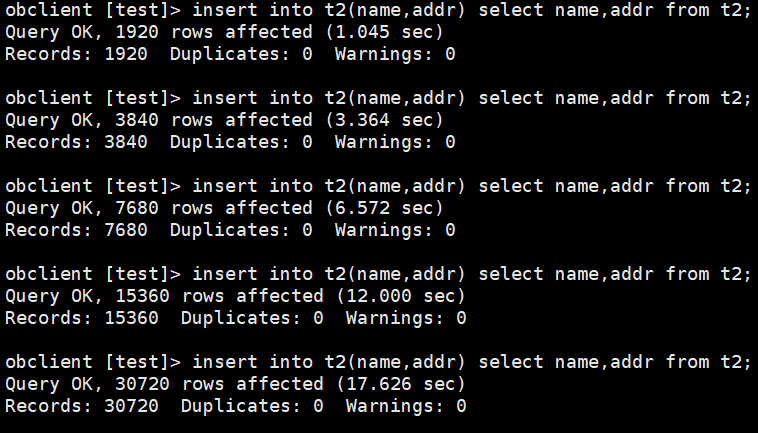
(4)执行完上图中的最后一个insert into select语句后,发现clog文件还没有写入与此事务相关的日志。

(5)再执行一次insert into select语句。

(6)看到observer日志中,显示出ob有日志回放的动作。能够看到也是回放的mutator日志。
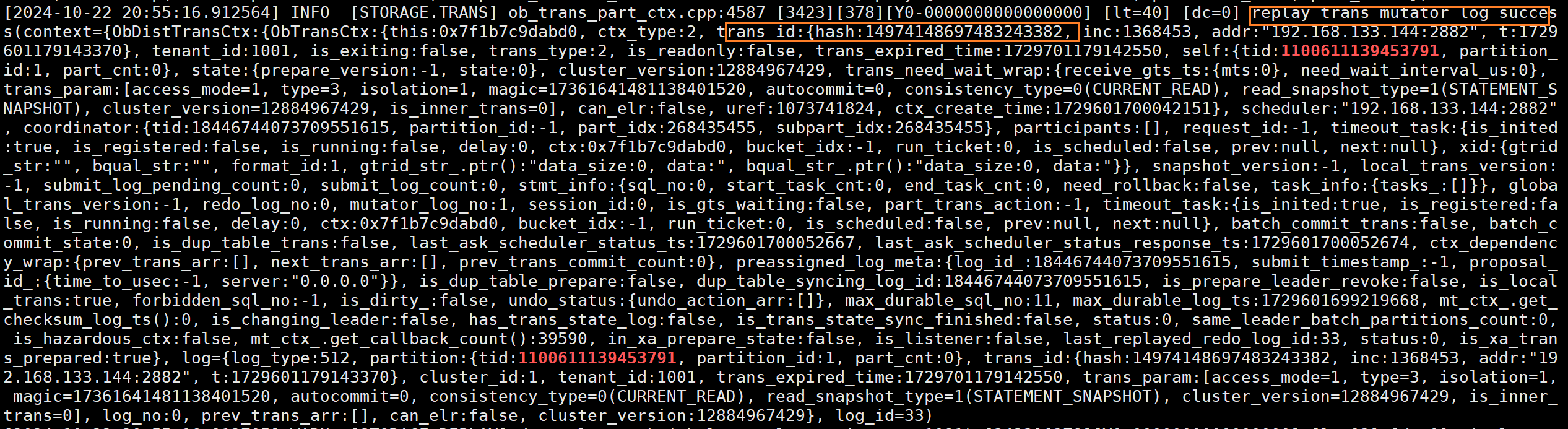
(7)这时还没有commit,但解析clog就已经能够看到大量mutator日志了,这些日志便记录insert的内容。
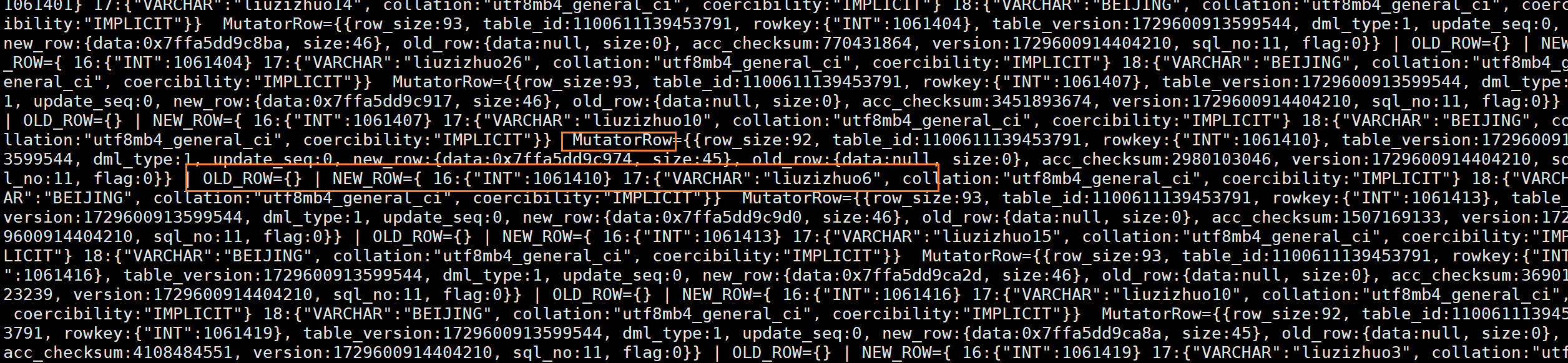
(8)日志很多拿了出来放在txt。单个节点的clog日志一共是3条mutator日志,1条是本地产生的clog,另外2条是其他分区leader传过来的,符合预期。
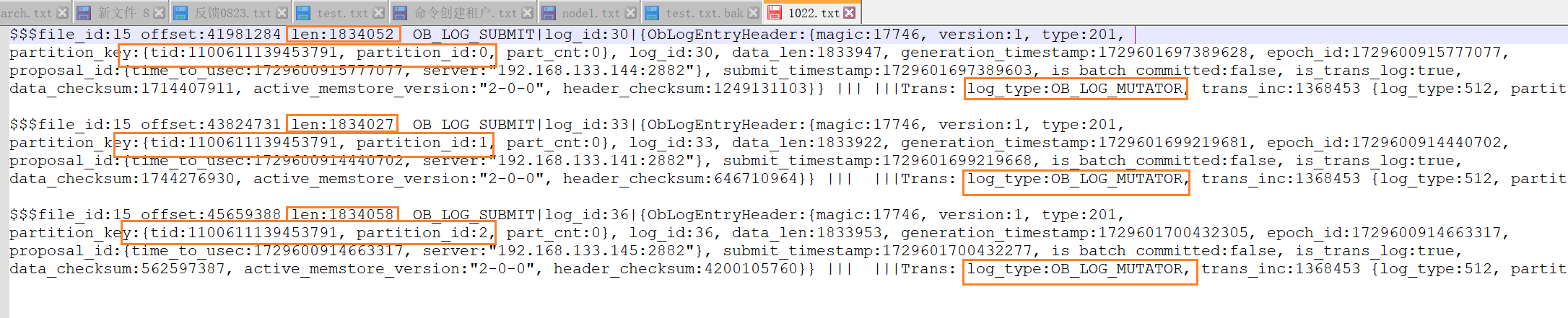 (9)为了排除是转储动作触发的同步clog的可能性,通过视图看到并没有发生转储,查到的最新的转储动作发生在前一日。
(9)为了排除是转储动作触发的同步clog的可能性,通过视图看到并没有发生转储,查到的最新的转储动作发生在前一日。
obclient [oceanbase]> select * from __all_server_event_history where event like "%minor%" order by gmt_create desc;
---------------------------- ----------------- ---------- -------- ------------------------- ----------- -------- ------- -------- ------- -------- ------- -------- ------- -------- ------- -------- ------------
| gmt_create | svr_ip | svr_port | module | event | name1 | value1 | name2 | value2 | name3 | value3 | name4 | value4 | name5 | value5 | name6 | value6 | extra_info |
---------------------------- ----------------- ---------- -------- ------------------------- ----------- -------- ------- -------- ------- -------- ------- -------- ------- -------- ------- -------- ------------
| 2024-10-21 21:48:53.814567 | 192.168.133.141 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | null | | | | | | | | | |
| 2024-10-21 21:48:52.176701 | 192.168.133.144 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | null | | | | | | | | | |
| 2024-10-21 21:48:50.272395 | 192.168.133.145 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | null | | | | | | | | | |
| 2024-10-21 21:48:45.184680 | 192.168.133.145 | 2882 | freeze | do minor freeze | tenant_id | 0 | | null | | | | | | | | | |
(10)之后执行commit并解析clog文件,看到ob_log_trans_redo日志、ob_log_trans_prepaee_with_redo日志、commit和clear日志。prepaee_with_redo日志此前已经遇到过,是记录prepare日志和redo的融合日志;ob_log_trans_redo日志则只记录redo,而且每条都不会超过1.875m,(8)中也能看到mutator日志也未超过1.875m。
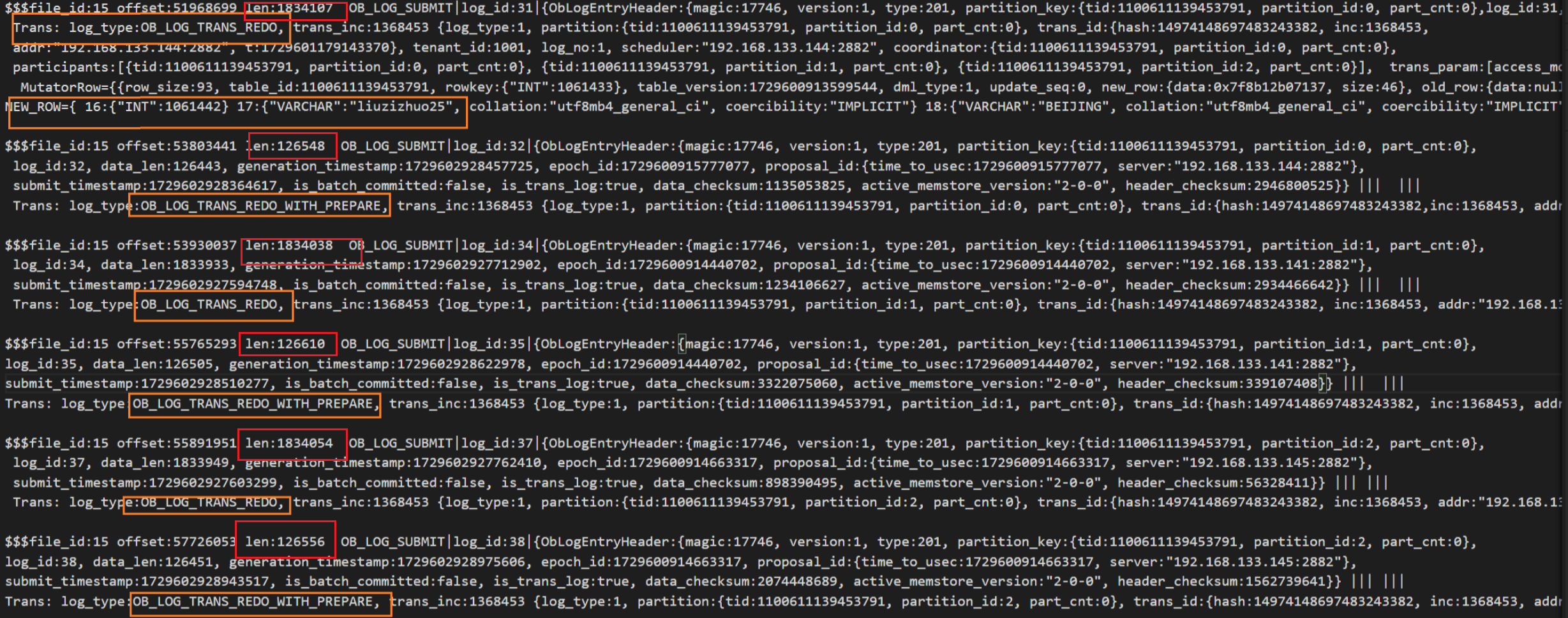
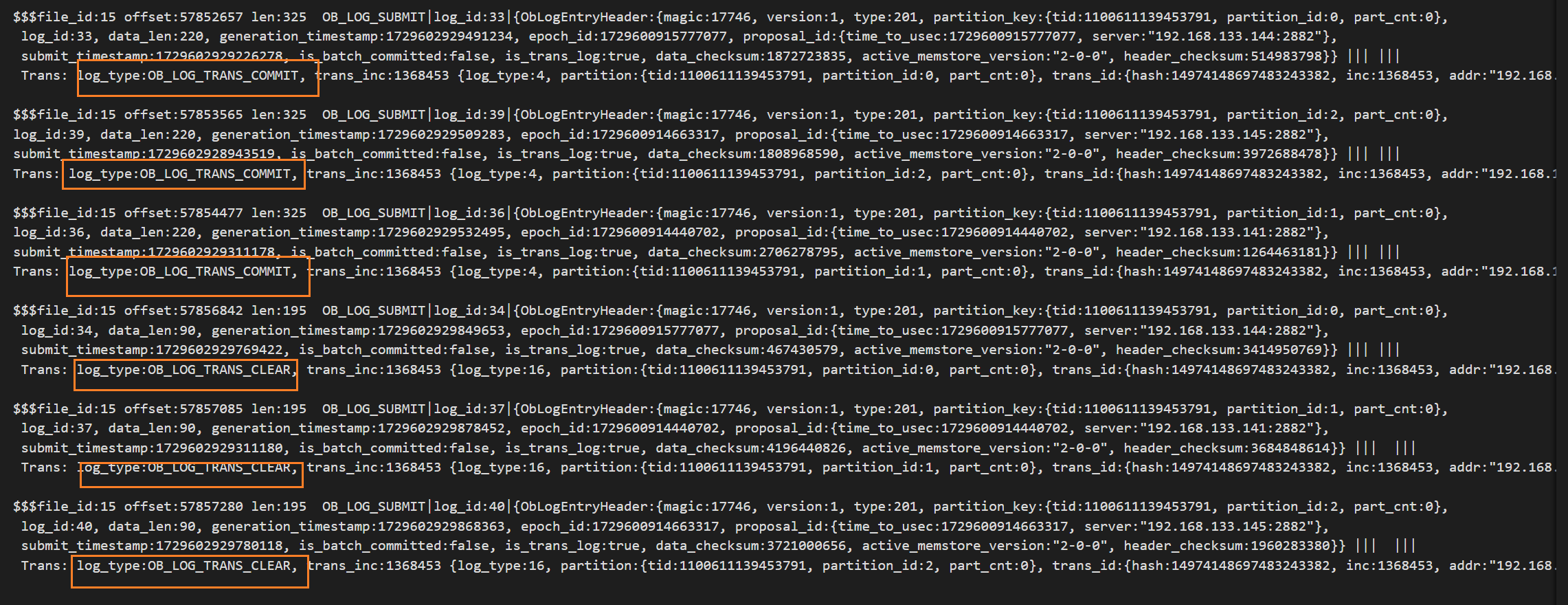
小结:通过实验可见在事务未提交的时候,就已经持久化并同步了一部分的redo,即ob_log_mutator所记录的数据变化。通过c7电子娱乐官网可知,当事务内存中数据达到2m时,leader副本会将redo持久化至本地并同步给follower节点进行回放,2m是由_private_buffer_size这个集群参数决定。这样做的最终目的是保证在主动切主时, 需要搬迁的数据量小于这一定值, 保证切主时需要同步的数据量可控, 达到平滑切主的目的。除此以外还发现clog中的日志不会超过某个值,搜索源码发现ob对单条日志大小有一个1.875m的限制。
四、总结
该篇文章的小实验都是基于ob v3做的,我猜想虽然ob v4有了日志流,但是两阶段提交、写入clog等现象还是一样的。
1) 客户端与observer建立会话并开启事务,建立起会话的节点即为调度者scheduler。事务中的sql经过sql引擎的解析后实施执行计划,实施执行计划的过程中调用存储层接口对分区进行增删改操作。很多时候一个事务会涉及到多个分区,这些分区即为分布式事务的参与者participant,对这些分区进行的增删改操作产生的新版本数据先去写入分区leader对应的memtable中,即对mvccrow上行锁并头插transnode对象。除了操作mvccrow对象,同时维护callback_list,以实现后续commit后的commit version回填和解行锁。
2) 随着事务中的sql不断执行,此事务的内存中的增量数据越来越多,当此事务内存中剩余需要同步的数据量大于__private_buffer_size(2m)后,ob将leader上进行的写入操作在本地持久化为ob_log_mutator日志,并将ob_log_mutator同步至follower节点的clog模块进行回放至内存的操作,同时follower节点持久化接收到ob_log_mutator日志。这种行为在ob中称为“即时写日志”。如果事务执行期间触发冻结而需要转储的话,也是执行和“即使写日志”相同的动作,即leader本地持久化ob_log_mutator日志并同步至follower副本。
3) 当客户端执行commit命令后,两阶段提交才算真正开始。
对于本地单分区事务,不走两阶段提交,而是一阶段提交:直接将剩余未持久化的写入操作连同commit操作一同持久化为ob_log_sp_trans_commit日志并同步至follower副本,多数派响应后即可告诉客户端commit完成。
对于分布式事务,commit后会将第一个参与写操作的参与者leader任命为两阶段提交的协调者coordinator,之后便进入两阶段提交的第一个阶段——prepare阶段。在这个prepare阶段,协调者向所有参与者leader发送两阶段提交的prepare请求,各个参与者将事务中剩余还未持久化为redo的写入操作持久化为ob_log_trans_redo_with_prepare(该日志融合了prepare日志和redo日志,prepare日志和redo日志也可能被单独分隔出来为ob_log_trans_prepare和ob_log_trans_redo日志),以上这些类型日志都还会被所有事务中的参与者leader同步至各自对应的follower副本去做持久化和回放。当多数派副本成功持久化这些日志后,这个参与者的写入操作才算被真正持久化了,参与者leader也会生成本地提交版本号(prepare version)并告知协调者。
注:上边提到的日志同步才会涉及到paxos accept,以达到对日志共识的目的、保证事务原子性,不要把paxos和两阶段提交搞混,这是两个不同维度的事情。
当所有参与者全部向协调者反馈自己的prepare version并告知协调者自己的prepare操作已经完成后,协调者取所有参与者中的最大prepare version作为事务的commit version,并将commit version再推给参与者并通知参与者进入pre-commit阶段,在pre-commit阶段各个参与者推高自己的max commit version,当所有参与者完成pre-commit并通知协调者后,协调者再响应客户端。
协调者响应客户端后,进入两阶段提交的commit阶段,首先参与者持久化commit日志ob_log_trans_commit并同步至对应的follower副本,协调者收到所有参与者持久化并同步完日志的消息后,将事务状态更新为clear状态,再通知所有参与者清空自己的上下文,同样需要持久化并同步clear日志ob_log_trans_clear。
至此事务生命周期也就结束了。
