oceanbase在传统监控数据存储的应用-c7电子娱乐
笔者从事于一家总部位于宁波,业界领先的新能源上市公司,公司业务涵盖光伏新能源产品的开发、制造及销售。
作为产值百亿的企业,监控系统是重要的it管理工具之一,对保障企业业务连续性、预告风险有重要意义。2022年,公司选用zabbix为企业监控系统,对公司分布在国内外的服务器、操作系统、中间件、数据库、网络设备等进行指标监控;对集团业务系统设置监控预警,确保集团所有系统异常时准确告警;对it设施的巡检、事件的回溯提供指标数据支撑,便于it管理人员可以快速获取系统中各个组件的历史数据。
监控业务架构介绍
之所以选择zabbix是因为其开源,且经过多年发展,不仅架构稳定还具备“监控万物”的能力,适合我们这种以传统架构为主,云原生架构比例很低的企业。公司内部相关it人员也有zabbix使用经验,上手门槛较低。
彼时,笔者刚加入公司,对刚上线的zabbix监控系统做持续且深度的优化和改造,不断提升监控系统的及时性、准确性。由于zabbix底层数据库使用mysql 8.0,被mysql的架构限制,因此,很快就出现了问题。
基于mysql的监控业务架构痛点
第一个问题,架构高可用瓶颈,无论选择哪种架构,都不尽人意。
- 主从架构的问题:
- 非读写方式,与单点的性能无差异不推荐。主节点故障后,需要停机切换,还需要校验主从节点的数据差异,所以不推荐。
- 读写分离方式有2种改造方式,一是改造dal层代码,这种方式影响后续版本功能的迭代,不推荐;二是引入如 proxysql的中间件,但增加了一层组件,在性能和可靠性上有所降低。
- 双主架构的问题:
- 单写是我们目前采用的方式,节点上套用一层keepalived作为虚拟地址,方便切换。
- 双写的话需要控制写入行的id,避免主键冲突和数据冗余。需要改造,不推荐。
- mgr架构的问题:
- 一致性强,但需要配合如proxysql之类的中间件实现读写分离。在实际测试中,mgr容易产生雪崩效应,即一个节点掉出后,可能导致整个集群崩溃。
所有采用复制方式的架构最大的问题点在于,zabbix的写入量很大,binlog不能保留太久(非常占用磁盘空间),如果复制关系断开太久会导致主从节点之间无法找到同步位点,无法重新同步上。
第二个问题,读写冲突。zabbix的写入量很大,在业务高峰时段,运维人员和业务人员查询监控数据、history数据向trends数据转换、告警比较等,很容易产生读写冲突(乐观锁)。但zabbix还有一个管家服务,会定期清理过期的监控数据,这容易造成悲观锁,使数据库性能急剧下降。在数据量不断增大的同时,这个冲突会越来越明显。
第三个问题,容量问题。尽管对监控项的数量、保留时间做了大量的改造,但仍有大量的数据需要保存下来。运行1年多,zabbix的数据库已经超过1tb,最大单表数据量超7亿。数据本身的容量只是问题中的其一,其二是innodb的binlog。
基于监控架构痛点,我们需要结合业务情况进行优化,下面是我们对优化的思考。
优化mysql难以解决根本问题
在众多优化案例里,笔者挑选了一个典型的数据优化案例来分享。
在制作zabbix监控模板时,其中linux操作系统监控模板的监控项就多达100个,面对公司2000 生产级别服务器,监控项规模达到了20w个,假设每隔5分钟对所有的监控项收集一次数据,那么,每小时数据库库中将有20w*(60/5)=240w 笔数据要写入history表。
5分钟采集一次是一种理想情况,因为采集间隔变大后,数据的精度会降低。对于一些流量数据、cpu、内存、i/o等使用率数据,用户往往要求以较高的精度采集,采集间隔可能是在1分钟左右,这样的代价是产生了更多的监控数据。
同时考虑到 history 到 trends 转换,每小时从hisoty 和 history_unit 表中取出完整1小时的监控值进行运算后(min、avg、max),分别 insert 到 trends 和 trends_unit 表中。
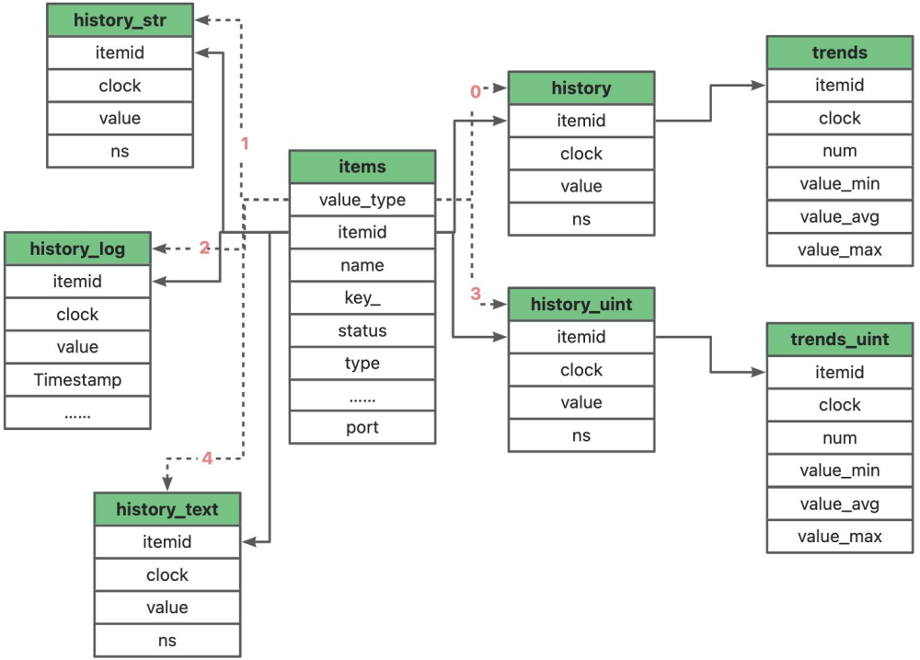
这个过程中,查询到的结果集大、运算量大,需要大量的缓存,往往引起mysql的临时表或临时表文件创建过快、磁盘i/o过大、占用swap、引发大事务等问题。
随着数据量的增大,以及上文提到的事务悲观锁冲突,导致在清理历史数据时,往往会清理任务失败,进而历史数据越积越多。同时,锁表的问题导致在环境中无法使用dump方式进行备份,只能使用物理备份。但在使用物理备份时,由于清理历史数据的过程中使用delete方式,造成主要业务表中的空间未得到正常释放,产生碎片,在备份前需要进行碎片整理,使得备份业务推进起来非常艰巨。
大批量的insert、delete操作使服务器的binlog变得庞大,导致存储压力很大。调小后,如果主从一断,主库上的binlog位点很快就会循环覆盖,导致从节点要重新恢复才能加入到集群。
对于上述问题,结合zabbix数据库中的数据表,我们就需要通过优化以下数据表来解决问题。
| 表名 | 作用 | 数据类型 |
| history | 存储原始的历史数据 | 数字(浮点数) |
| history_uint | 存储原始的历史数据 | 数字(无符号) |
| history_str | 存储原始的短字符串数据 | 字符型 |
| history_text | 存储原始的长字符串数据 | 文本 |
| history_log | 存储原始的日志字符串数据 | 日志 |
| trends | 存储每小时统计数据(趋势) | 数字(浮点数) |
| trends_uint | 保持每小时统计数据(趋势) | 数字(无符号) |
| auditlog | 审计日志表 |
history 开头的表为存储历史数据,trends开头的是趋势数据。历史和趋势是在zabbix中存储数据的两种方法。
- ,历史保存着每一个item的数据。即从客户端收集过来的原始数据,这部分表的表结构都差不多,唯一的不同是保存的数据类型。如果一个监控项(item)一分钟采集1次,那每天就有24*60*60=86400笔数据。
- itemid bigint(20)、clock int(11)、value bigint(20)、ns int(11),大概一笔数据是8 4 8 4=24 b,一天有24*86400≈2 mb;
- history_str 或者 history_text 两个表,其中的数据字段变成了value varchar(255) collate utf8mb4_bin 和 value text collate utf8mb4_bin ,varchar(255) utf8mb4 最长是 255*4=1020 b,而text 字段最大可以到65535 b ,我们考虑极端情况,一个字符型或文本型的 item ,按1分钟采集1次,分别对应产生的数据量为(8 4 1020 4)*86400≈85 mb 或 (8 4 65535 4)*86400≈5 gb ;
- ,是每小时监控的数据聚合后的结果,保存一小时内某个item的平均值、最大值和最小值,可以理解为是history表的压缩数据,因此减少了对资源的需求。
- 仅针对数值类型的 history 表,而 history_str 、history_log 和 history_text 是没有趋势表的;
从索引开始
表中存在2个时间字段,一个是clock,另外一个是ns,接收item值时的时间值存放在两个字段内,大于1秒的部分存放找clock字段单位是秒(s),小于一秒的部分存放在ns字段单位是纳秒(ns)。
ns上面做索引,导致了全表扫描,所以我们将history表进行改造:
create table `history_old` (
`itemid` bigint(20) unsigned not null,
`clock` int(11) not null default '0',
`value` double not null default '0',
`ns` int(11) not null default '0',
key `history_1` (`itemid`, `clock`) block_size 16384 local
) default charset = utf8mb4
create table `history` (
`itemid` bigint(20) unsigned not null,
`clock` int(11) not null default '0',
`value` double not null default '0',
`ns` int(11) not null default '0',
primary key (`itemid`, `clock`, `ns`)
) default charset = utf8mb4
其余history表的改造参照上面的方法
表分区
history系列表和trends系列表进行分区,定期create 分区和drop 分区。在做分区管理时,遇到三个问题。
insert /* enable_parallel_dml parallel(2) */ …… select …… 的方式处理(这里用到了ob dml的并行,具体可以参考https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000001050810),但发现部分数据量少的表还能够导数成功,大表、业务繁忙的表根本无法执行。
第二,如果我们使用dump方式去备份还原表,中间停机时间要很久。
datax做数据同步的话,什么时候追平数据,如果中途停止,找最后位点的难度很大。
mysql参数优化
tmp_table_size、innodb_log_buffer_size、 sort_buffer_size、read_buffer_size、join_buffer_size、binlog_cache_size的大小,尽可能将数据留在内存中,加快数据的处理速度。
但是无论如何优化buffer,也不能无限制的增大,当达到物理内存的上限时,就需要去扩容内存。同时,大量的大事务会过度消耗磁盘i/o(当脏页达到一定量的时候就会落盘,落盘就会产生i/o),加剧数据库的压力。底层物理设备的扩容会涉及停机、迁移等中断服务的事件,也是额外增加成本。
可见,在mysql及操作系统的调优和扩容硬件的方法始终会有尽头或者瓶颈,不是最优解,我们需要寻找新的出路。
寻找新的出路
对于新的数据存储方案,我们希望除了能够解决现有架构瓶颈和业务痛点外,还需要具备三个条件:
1. 必须兼容mysql的语法、函数与表达式、数据类型、表分区、字符集、字符序。
2. 具备htap能力,能够在基于关系型数据结构在数据引擎层面处理好tp和ap的关系。
3. 在不依托于其他技术手段的情况下具备高可用、多活能力。
mysql、postgresql,但团队中没有人熟练驾驭postgresql,同时,在zabbix的 mysql 数据库上已经开发了比较多的应用、报表,如果贸然将数据库从mysql切换成postgresql,需要对之前的应用、报表做再开发,因此,暂时不考虑postgresql,于是将选型的范围放在兼容 mysql 模式的数据库。
innodb引擎,mysql的tokudb引擎作为innodb引擎的优化升级版本,就成为了我们选型数据存储方案中的备选。
tidb、华为gaussdb和opengauss、oceanbase、达梦数据库。
- tidb不支持mysql的存储过程、外键,首先排除。
- opengauss基于postgresql,与postgresql数据库一样,作为第二梯队方案。
- 华为gaussdb需要付费购买,暂时不考虑。
- 达梦数据库需要付费购买,暂时不考虑。
oceanbase兼容mysql,支持分布式,而且开源,可以进行下一步调研。
tokudb引擎、oceanbase作为优选方案。
| 对比项 | tokudb | oceanbase |
|---|---|---|
| 部署难易度 | 较容易 | 较容易 |
| 容灾架构 | 主从 | 分布式 |
| 数据压缩比 | 中 | 高 |
| 信创支持 | 无 | 支持 |
| 性能对比 | 优化了写入,但读性能缺少依据 | 未测试 |
综合考虑下,由于tokudb读能力不满足预期,oceanbase支持htap、多活高可用,以及社区活跃,有非常多的参考资料,容易上手。因此,我们最终决定使用oceanbase。
上线oceanbase
总的来说,oceanbase的上线流程较为顺利,从 myysql 迁移到 oceanbase非常容易。因为我们用的是oceanbase 社区版,所以,在迁移前无法使用迁移评估(oceanbase migration assessment,oma)来对迁移过程进行评估,只能依靠经验来判断,在社区的官方人员和社区用户群朋友们的帮助下,我们在迁移前做了如下检查,供大家参考。
- oceanbase没有完整支持mysql的字符集和排序,所以,需要在迁移前做好评估。
- 中没有event,原库中有event时,需要通过别的方法实现,后文列举了案例。
- lower_case_table_names的配置。
- omstxndb库建立好。
- set foreign_key_checks=0;

。此外,上文中提到的在zabbix的history相关表,trends相关表需要实现表分区。分区管理需要定时任务,否则管理员定期维护分区的工作量很大。在mysql中,我们可以通过event 存储过程的方式来实现自动化。而由于oceanbase中没有event,这似乎又要碰壁了。俗话说:“当门关上的时候,会给你开一扇窗”,因此,我们可以使用oceanbase 的odc(开发者中心。oceanbase developer center)来实现,这是一个开源的企业级数据库协同开发平台。里面集成了“分区计划”的模块,可以将其看作mysql中的event 存储过程方案的plus版本。具体可以看我之前的博客:https://open.oceanbase.com/blog/12521093139
新库新征程
在写本文时,我们的zabbix监控系统已经在oceanbase中运行了半年,相比之前使用mysql时,从资源配置上来讲,在获取相同性能的情况下,可以大幅降低硬件平台的投入。
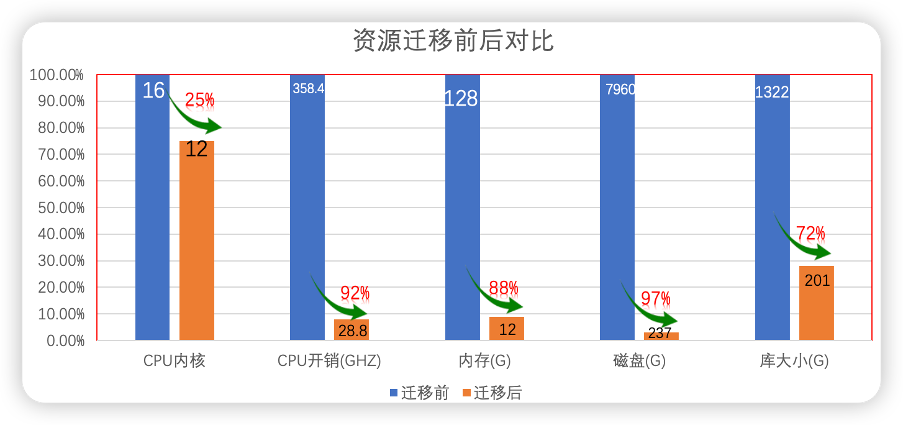
最初,由于oceanbase兼容mysql,公司的开发人员和系统管理人员对于数据迁移并没有表示反对,在迁移过程中,oceanbase的高可靠、htap等能力使笔者在与业务系统运维部门沟通迁移计划时都比较顺利,迁移后带来的性能提升和80%的空间节约,也让业务部门非常满意。
在性能提升方面,最直观的感受是之前在查询周期较长的历史数据(几周或几个月)时,通常需要好几秒(至少4秒)时间才能将数据渲染出来,现在运行在ob上之后,基本上点击完后就可以立即加载出统计图;另外一个感受就是,以前zabbix有各种各样的性能告警,频度也比较高,自从迁移到ob上之后,此类告警明显减少。
总而言之,oceanbase是一个符合我们预期的数据库平台,目前,我们也在不断探索和实践oceanbase的新功能。以下,我将结合公司业务场景与oceanbase的功能进行简单总结。
此外,oceanbase丰富的生态工具也为我们带来了更加自动化、更加便捷的运维管理能力。
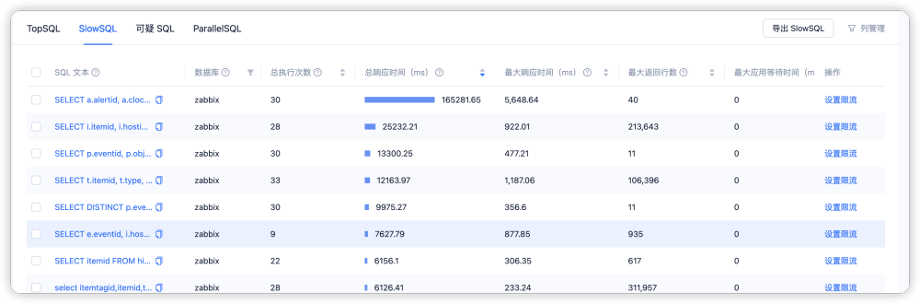
- sql诊断:集成sql诊断功能,便捷、快捷的观测topsql、slowsql、并行sql。可以通过可视化的手段,观测sql的执行情况、快速诊断。
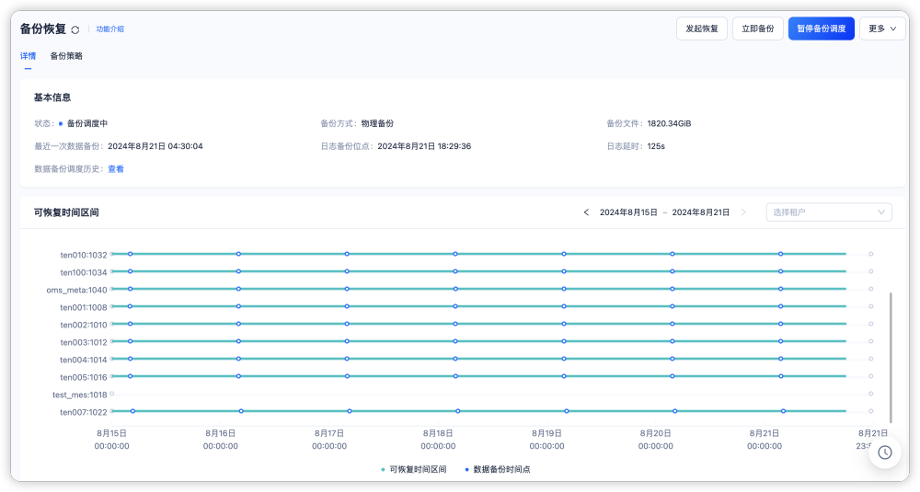
支持 oceanbase-ce、mysql、postgresql、tidb、kafka 和 rocketmq 等多种类型的数据源与 oceanbase 社区版进行实时数据传输,以及 oceanbase 社区版 mysql 租户间的数据迁移。
最后,odc作为开发者中心,提供了许多便捷的功能,比如:
- 》。
憧憬未来
对于oceanbase的这些特性,结合我们实际的业务,未来会将更多的库迁移到oceanbase上面来。目前正在进行的有生产设备数据采集系统(下称:数采系统)、报表系统的迁移。
执行计划不仅难读,还抖动、恶化,导致sql在执行时候不稳定,而且系统日志理解困难,另外对于中文的支持还是有提升空间,我们在测试obdumper时,遇到了中文表名备份失败的问题(目前社区还在分析,临时方案是回退到了一个旧版本来解决)。
的功能非常强大是事实,每一个事务都在不断进步。从我们试用到使用oceanbase的过程中,有“坑”也有惊喜,遇到问题,先看手册,自己思考。如果自己想不明白可以再社区的问答板块和用户答疑群寻求帮助,社区的老师会及时答复(相较于其他开源社区,oceanbase的及时性和准确性要好很多)。
还在不断发展,对于4.3版本中的列存、物化视图等功能还等着我们探索,道阻且长,行则将至。


